
《IOT废物学习之路》(1)--MIPS交叉编译环境搭建以及32位指令集
《IOT废物学习之路》(1)–MIPS交叉编译环境搭建以及32位指令集
先介绍一下指令集
一、指令集
指令集大体上可以分为两大类:
- CISC(complex instruction set computer)(复杂指令计算机)
- RISC(reduced instruction set computer)(精简指令计算机)
(1)CISC复杂指令架构
特点是拥有丰富而复杂的指令集。CISC架构的设计思想是通过一条指令执行多个低级操作,以实现高级编程语言中的复杂操作。所以,CISC处理器的复杂性和内部控制逻辑可能会导致较低的时钟速度和较高的功耗。像我们经常接触到的x86、x86-64等指令集都是CISC架构的具体表现。
(2)RISC复杂指令架构
特点是简单且精简的指令集。RISC架构的设计思想是将处理器的指令集保持简单和精简,以提高指令执行速度和效率。所以,RISC处理器的指令集包含较少、更加基本的指令、这些指令执行的操作通常是单一的,且需要相同的数量的时钟周期来执行。像ARM、MIPS等用于嵌入式等指令集都是RISC架构的具体表现。
二、CISC和RISC的区别
1、指令集复杂性:
- CISC架构具有复杂的指令集,一条指令可以执行多个操作,包括算数运算、内存访问、控制流操作等。CISC指令通常具有不同的格式和变长指令,支持丰富的寻址模式。
- RISC架构具有精简的指令集,每条指令执行的操作通常是单一的,且指令长度是固定的。RISC架构鼓励使用寄存器寻址,减少内存访问(加快访问速度)。
2、硬件设计:
- CISC处理器硬件设计较为复杂,因为需要支持多功能的指令。通常有复杂的控制逻辑和微码来执行不同的指令。
- RISC处理器硬件设计相对简单,因为指令的执行步骤都是均匀的。这有助于提高处理器的时钟频率和性能。
3、时钟周期:
- CISC由于复杂的指令和硬件设计,CISC处理器的时钟周期通常较长,执行一条指令需要多个时钟周期。
- RISC处理器通常具有较短的时钟周期,由于指令的长度是相同的,所以执行每条指令通常只需要一个时钟周期。
4、流水线:
- CISC处理器流水线较短,因为一条指令通常需要多个时钟周期。
- RISC处理器的流水线较长,允许在每个时钟周期内同时处理多个指令。
5、分支指令:
- CISC处理器的分支指令通常有较长的延迟,因为它们可能需要多个时钟周期来解析和执行。
- RISC处理器通常用延迟曹(delay slot)来减少分支延迟,允许在分支后执行一个额外的指令。
6、编译优化:
- CISC指令集较为复杂,编译器可能需要更多的工作来生成有效的机器代码。
- RISC指令集更容易进行编译优化,编译器可以更轻松地生成高效的代码。
CISC架构适用于需要丰富的指令集和高级抽象的应用,如通天计算机。
RISC架构适用于需要高性能、低功耗和简单硬件设计的应用,如嵌入式系统和移动设备。
总结来说:
RISC和CISC的共同点都是对指令集的描述,但是RISC对于CPU的流水线架构的实现影响比较大,而CISC指令集对于架构的影响不大。虽然,现在的X86架构大量借鉴了RISC的一些实现技巧,用来提升自己的性能。但其本质上还是复杂指令集计算机(CISC)架构。
接下来详细介绍一下“主角”——MIPS架构
三、MIPS架构
众多RISC精简指令集架构中,MIPS架构是最优雅的。MIPS架构还是以最简单的设计成为每一代CPU架构中,执行效率最快的那个。
MIPS架构主要研究方向还是CPU的流水线架构,让他如何更高效地工作。
流水线的互锁是影响CPU指令执行效率的关键因素之一。
MIPS的五级流水线
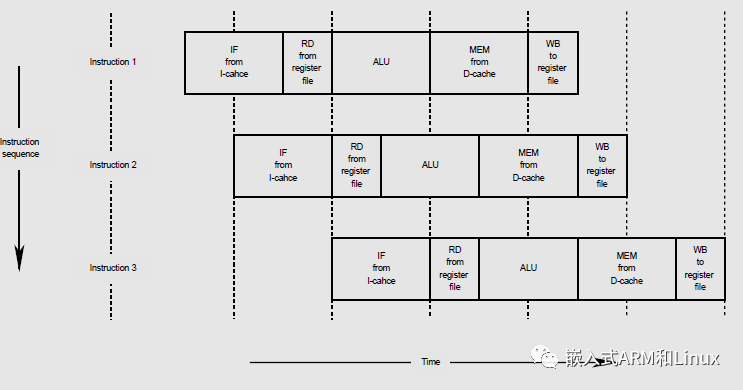
MIPS本身就是基于流水线优化设计的架构,所以,将MIPS指令分为5个阶段,每个阶段占用固定的时间,在此,固定的时间其实就是处理器的时钟周期(有2个指令花费半个时钟周期,所以,MIPS的5级流水线实际上占据4个时钟周期)。
一共有五个阶段:
- 取指令-IF
从I-Cache(指令缓存)中取要执行的指令。
- 读寄存器-RD
取CPU寄存器中的值。
- 算术、逻辑运算-ALU
执行算数或逻辑运算。(浮点运算和乘除运算在一个时钟周期内无法完成)
- 读写内存-MEM
就是读写D-Cache(数据缓存)。因为内存的读写速度太慢了,无法满足CPU的需要。所以出现了D-Cache这种高速缓存。即便如此,但在读写D-Cache期间,平均每4条指令就会有3条指令什么也做不了。但是,每条指令在这个阶段都应该是独占数据总线的,不然会造成访问D-Cache冲突。
- 写回寄存器-Writeback
将结果写入寄存器。
上面的流水线只是理论模型,但是5级流水线架构是一切的出发点和基础。
四、MIPS交叉编译环境搭建
实验环境

ubuntu版本为–ubuntu 22.04 LTS
kernel版本为–6.2.0-33
实现交叉编译所需依赖库如下:
1 | !/bin/sh |
再搭配上pwndbg和pwntools。
五、MIPS交叉编译环境测试
测试代码:
1 |
|
和x86一样,MIPS也分为大端序和小端序、32位和64位,编译不同类型的可执行文件所需要的命令如下:
32位小端序:
1
mipsel-linux-gnu-gcc -g test.c -o test_mipsel_32
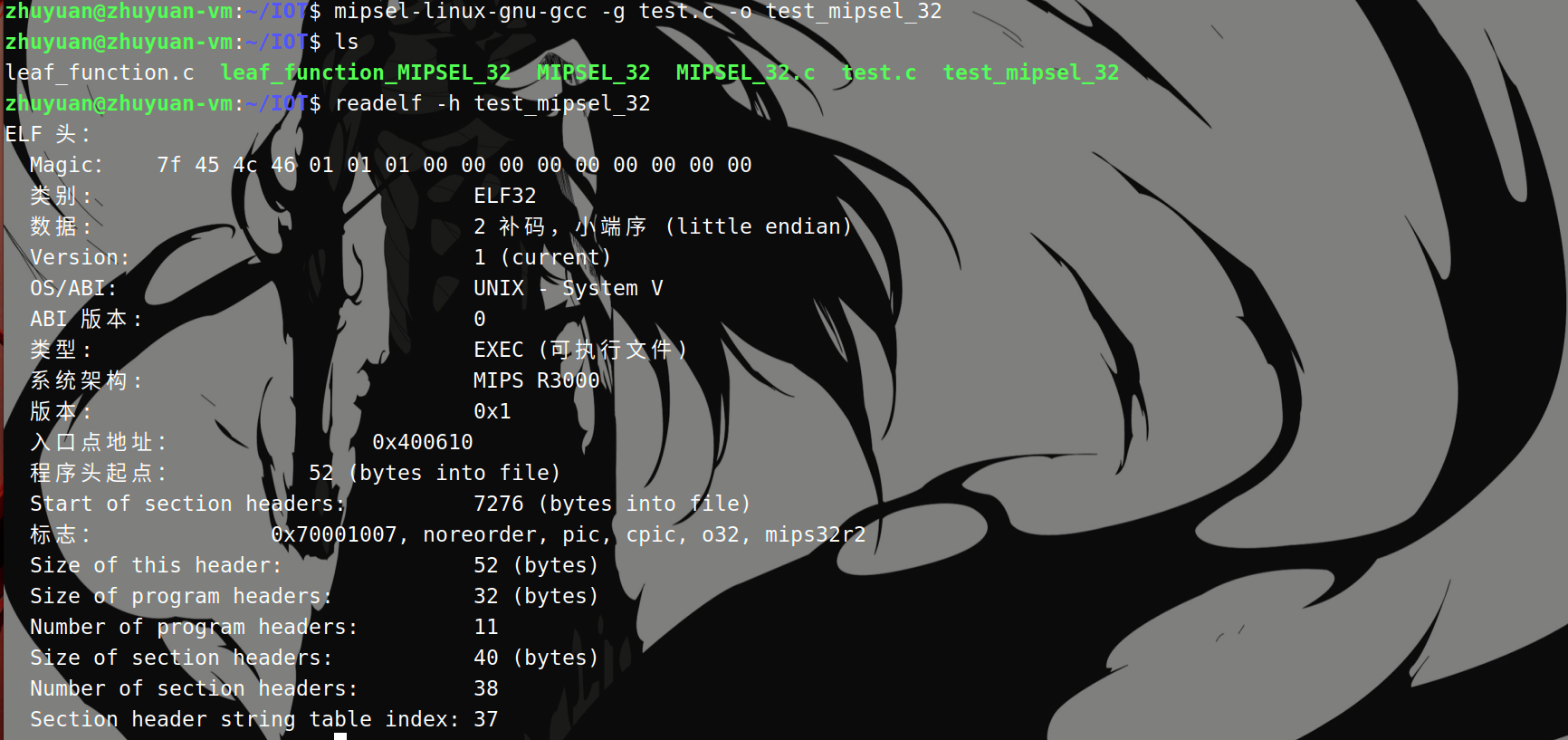
32位大端序:
1
mips-linux-gnu-gcc -g test.c -o test_mips_32
64位小端序
1
mips64el-linux-gnuabi64-gcc -g test.c -o test_mips64el_64
64位大端序
1
mips64-linux-gnuabi64-gcc -g test.c -o test_mips64_64
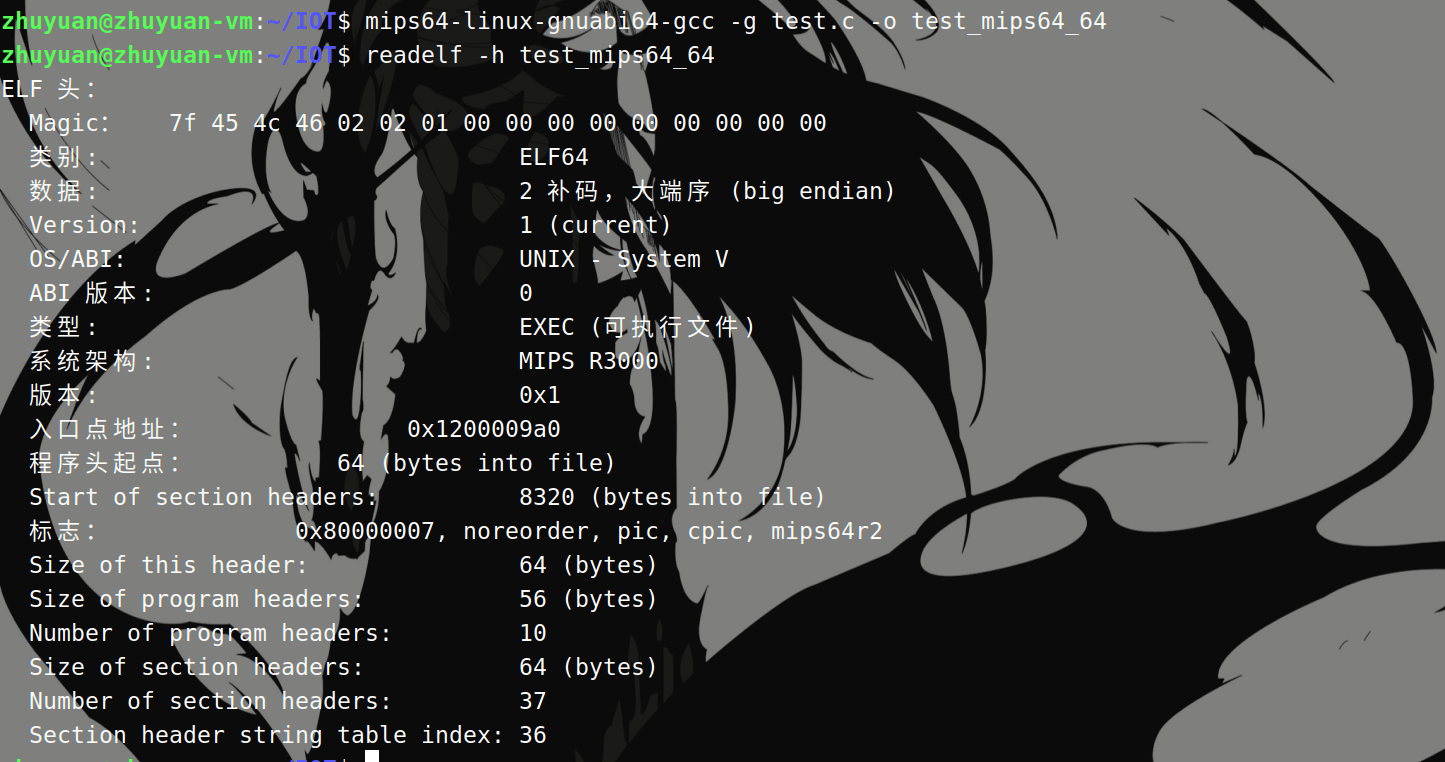
编译出的文件保护均为默认开启Canary、半开RELRO、其它保护均为关闭状态。
qemu模拟运行
介绍qemu
QEMU 是一个快捷的跨平台开源计算机模拟器,可以模拟许多硬件体系结构。QEMU 可以在现有系统(VM 主机服务器)之上运行未经修改的完整操作系统 (VM Guest)。还可以使用 QEMU 进行调试 — 可以轻松停止正在运行的虚拟机、检查其状态、保存并在以后恢复其状态。
总之来说,因为我们不是处在真实的mips环境中,但是我们可以利用qemu模拟出mips所需要的硬件环境。
利用上面编译后的test_mipsel_32文件使用qemu模拟运行,由于这个可执行文件是动态链接,所以需要在运行时额外指定对应的动态链接库:

ubuntu下依赖的动态链接库存放在**/usr/**目录下:

六、32位MIPS指令集
MIPS寄存器
无论是32位还是64位,在MIPS中均有32个通用寄存器(General-Purpose Register),可以从$0到$31给它们编号,各个通用寄存器的详细信息如下表所示:
| 寄存器编号 | 名称 | 功能 |
|---|---|---|
$0 |
$zero |
常量寄存器(Constant Value 0),永远为0 |
$1 |
$at |
汇编暂存器(Assembly Temporary),用于处理在加载16位以上的大常数时使用,编译器或汇编程序需要把大常数拆开,然后重新组合到寄存器里。 |
$2~$3 |
$v0 ~$v1 |
用于存储表达式或者函数返回的值(value) |
$4~$7 |
$a0~$a3 |
存放函数调用时的参数(Arguments) |
$8~$15 |
$t0~$t7 |
存放临时变量(Temporary variable) |
$16~$23 |
$s0~$s7 |
保存(saved)寄存器,在函数调用和返回时可能需要保存和恢复寄存器的值。 |
$24~$25 |
$t8~$t9 |
同t0~t7 |
$26~$27 |
$k0~$k1 |
使用编译器编译出来的程序不会使用这两个寄存器,这两个用于保存异常处理和中断的返回值,为操作系统保留(keep)使用。 |
$28 |
$gp |
全局指针(Global Pointer) |
$29 |
$sp |
栈指针(Stack Pointer),指向栈顶 |
$30 |
$fp/$s8 |
$30可以当作第9个Saved寄存器$s8,也可以当作栈帧指针$fp使用,看编译器类型 |
$31 |
$ra |
保存函数的返回地址 |
以上只是通用寄存器。
MIPS架构最多支持4个协处理器(Co-Processor),该架构强制要求存在协处理器CP0,因为MMU、异常处理、Cache控制、断点控制等功能都依赖于CP0实现:
$sr:全称Status Register(状态寄存器),它位于CP0的Reg12,该寄存器可以反应CPU的状态以及控制CPU,其中较为重要的是8个中断控制标志位IM(Interrupt Mask)和标识着处理器大小端的RE(Reverse Endianess)
gdb中可以使用p/x $sr查看Status Register的值:

$lo、$hi:这两个寄存器用来存放整数乘除法的结果,可以使用mthi和mtlo指令对$hi、$lo寄存器进行操作。特别的,在除法计算中,$lo存放运算之后的商,而$hi寄存器存放余数。这两者不是通用寄存器,只能用于乘除法。$pc:Program Counter(程序计数器),类似于x86的eip,标志着当前要执行的指令。$f0~$f31表示浮点寄存器

MIPS指令
源码:
1 |
|
编译生成可执行文件
1 | mipsel-linux-gnu-gcc -g MIPSEL_32.c -o MIPSEL_32 |
qemu模拟
1 | qemu-mipsel-static -L /usr/mipsel-linux-gnu -g 1234 ./MIPSEL_32 |
gdb脚本调试
1 |
|
启动调试
1 | gdb-multiarch -x MIPSEL_32_script.gdb |
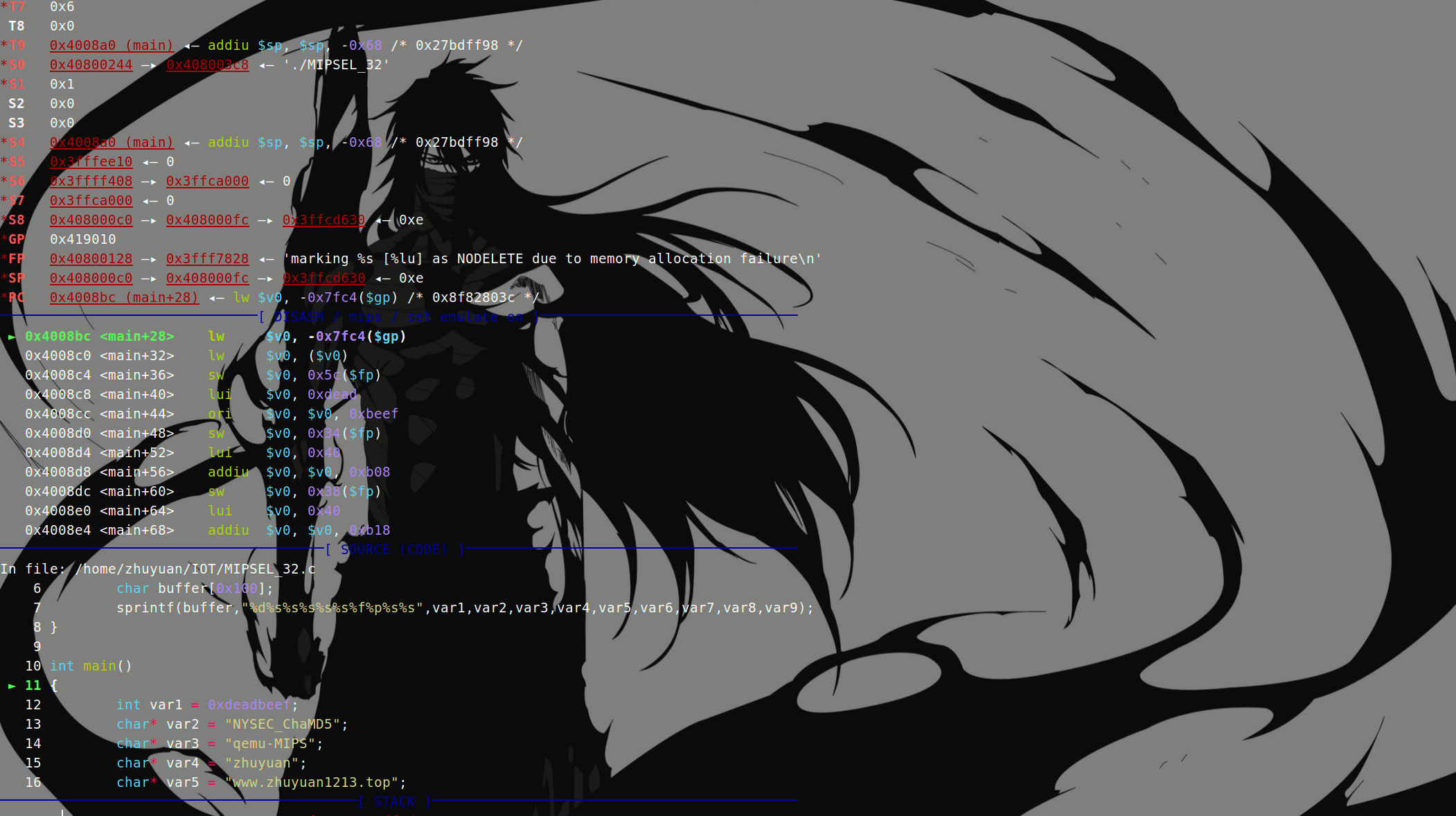
main函数汇编:
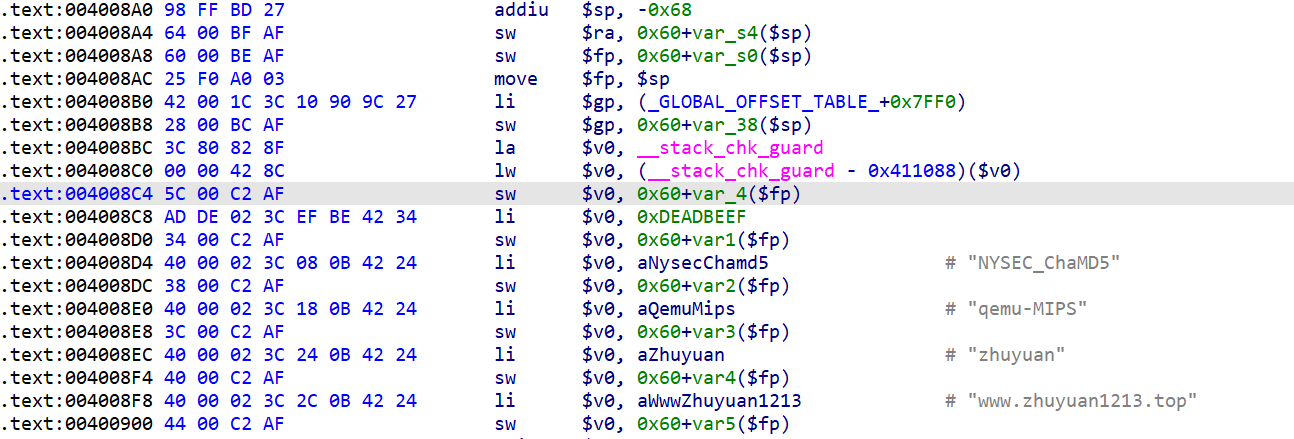
讲解一下上述指令:
addiu:add immediate unsigned,即,为左侧操作数加上立即数,但与addi不同的是addiu不会检测最终结果是否溢出。举例:addiu $sp, -0x68等价于$p = $sp -0x68。sw:store word,将寄存器的值保存到某地址。举例:sw $ra,0x60+var_s4($sp)等价于*($sp + 0x60 + var_s4) = $ra。move:用于寄存器之间值的传递。举例:move $fp,$sp等价于$fp = $sp(赋值语句)li:load immediate,用于将立即数传送给寄存器。举例:li $gp,(_GLOAL_OFFSET_TABLE_+0x7FF0)等价于$gp = (_GLOBAL_OFFSET_TABLE_+0x7FF0)la:load address,用于将地址传送至寄存器中,多用于通过地址获取数据段中的地址。lw:load word,从某地址加载一个word类型的值到寄存器中。举例:lw $gp,0x10($fp)等价于$gp = *($fp + 0x10)。

lui:load upper immediate,取立即数并放到寄存器的高16位,剩下的低16位使用0填充。lwc1:load word coprocessor 1,将浮点数加载到浮点寄存器。swc1:store word coprocessor 1,将浮点寄存器的数据保存到相应的内存。jalr:jump and link register,其格式为jalr oprd1 oprd2或jalr oprd1,当格式为前者时在调用函数后会将返回地址存入oprd2中;当格式为后者时返回地址将保存到$ra寄存器。nop:和x86的含义一样,滑动指令。
调用库函数malloc之后,接下来程序要为调用funny_function做准备:
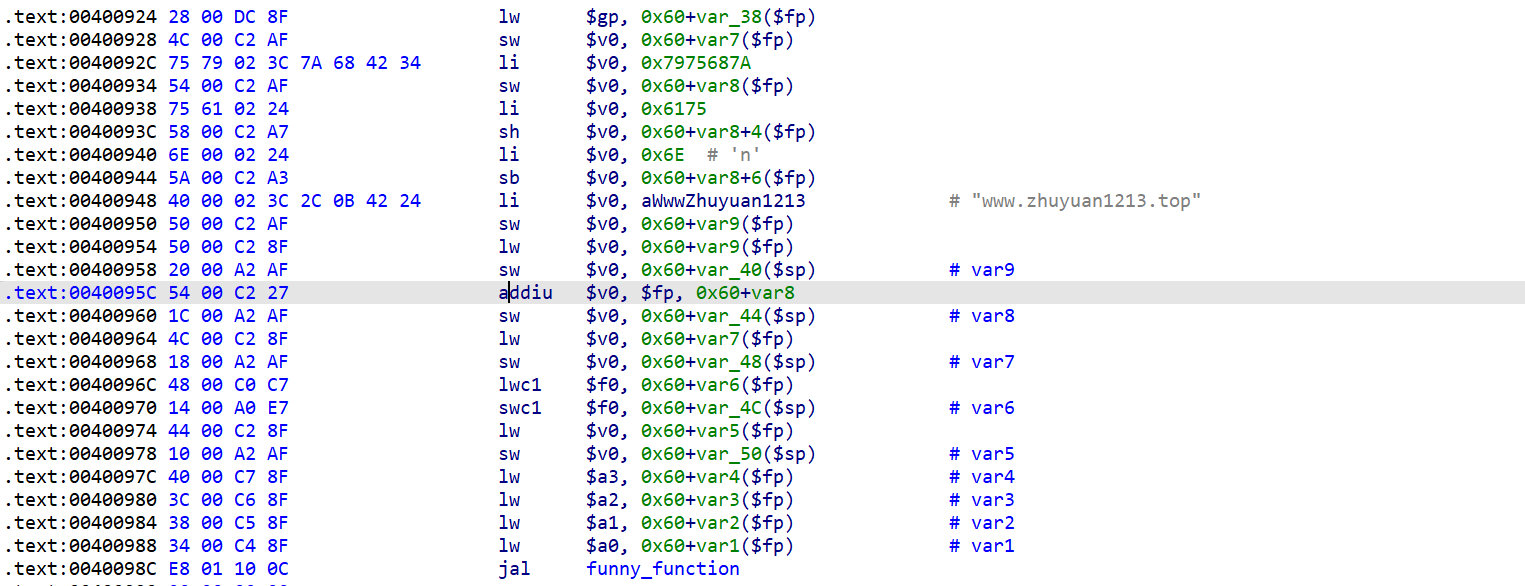
lhu:load halfword unsigned,加载半个字(1字节)的数据到目标寄存器中。sh:store halfword:传送半个字到目标内存。
我们在funny_function入口处下断点,运行来到0x4007a0处。
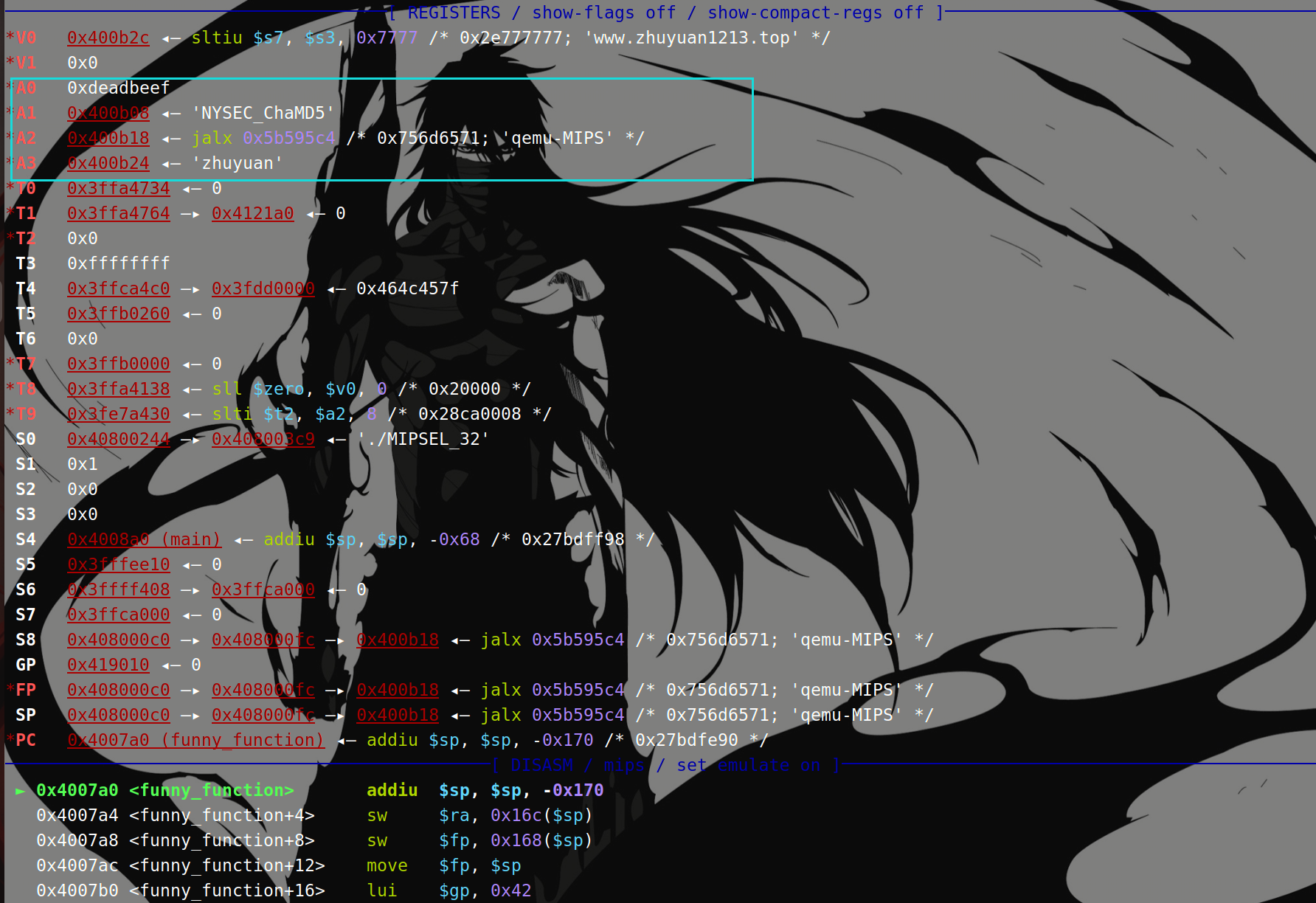
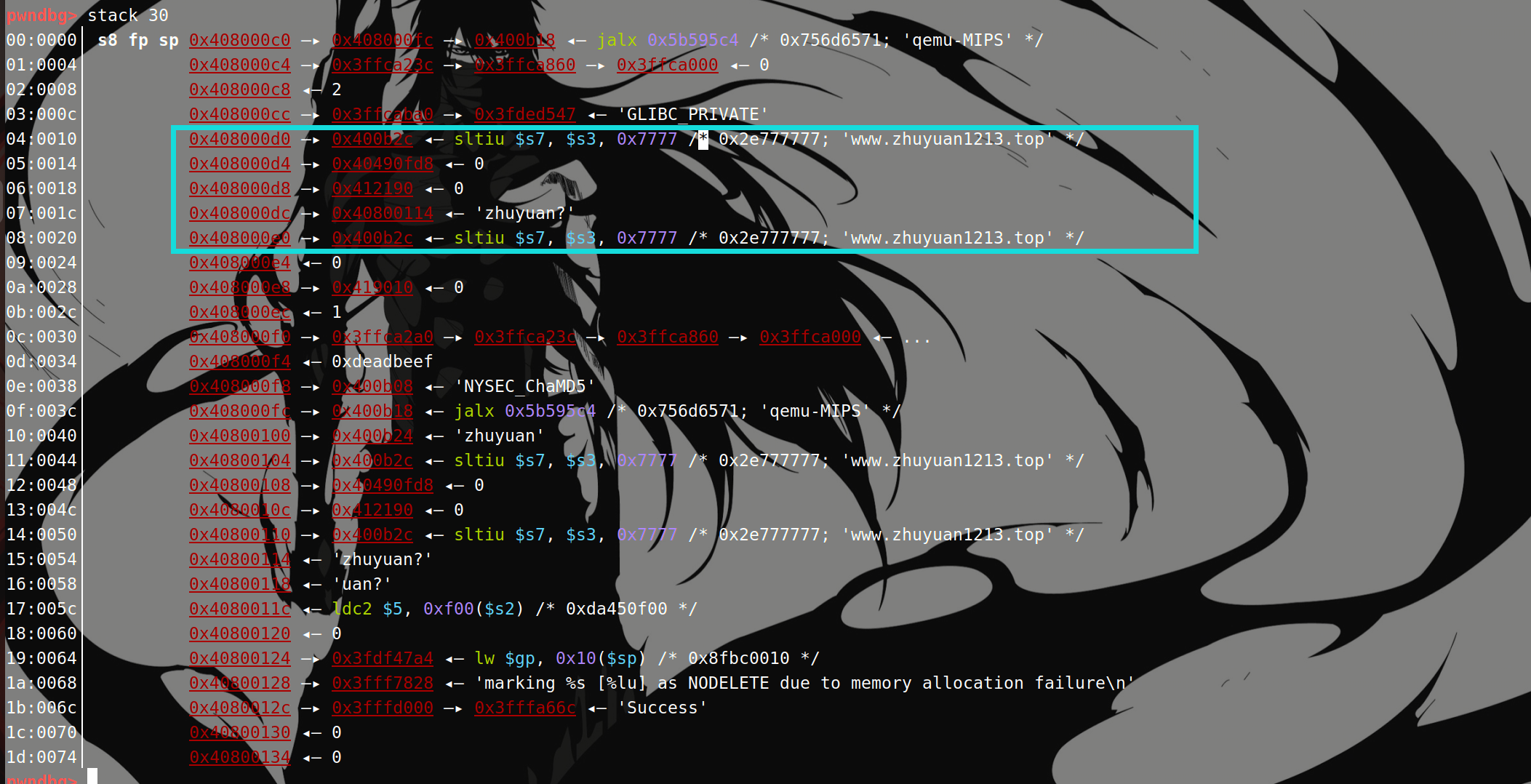
第一张图中是寄存器保存的前四个参数,第二张图是栈中保存的后五个参数。
所以可以看出,在MIPS32位下进行函数调用时,前面四个参数分别依此通过A0、A1、A2、A3寄存器传参,剩下的参数使用stack进行传递;而且虽然前四个参数没有使用栈传递,但是栈上仍然保留了这四个函数的位置。
进入到funny_function函数中,在函数调用的开头会将通过寄存器传入的参数复制到stack上,并且通过stack传送的参数要复制到新的栈帧中:
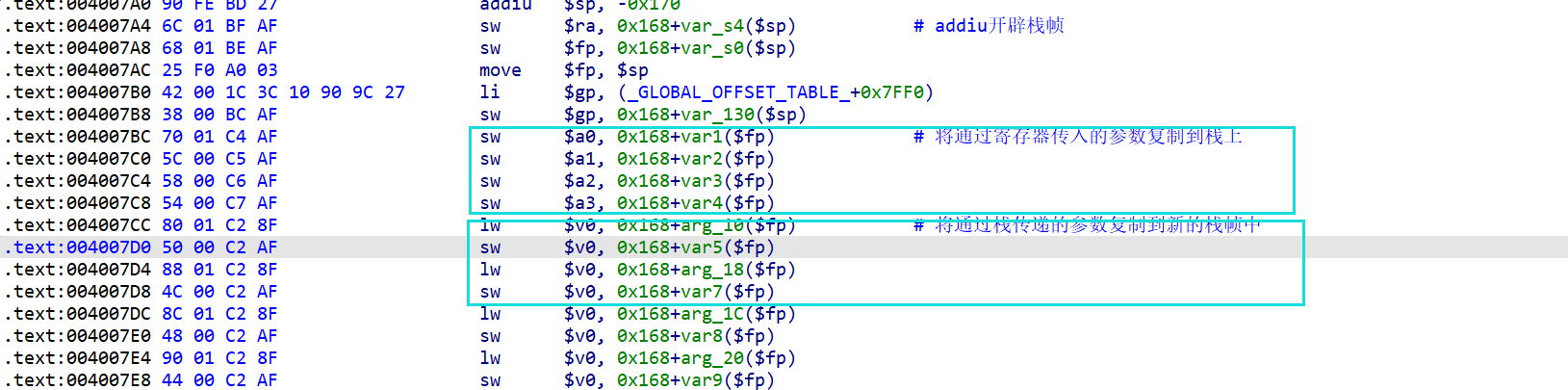
MIPS的函数在准备好参数之后,因为该文件开启了Canary保护,所以还要准备一下Canary的值:
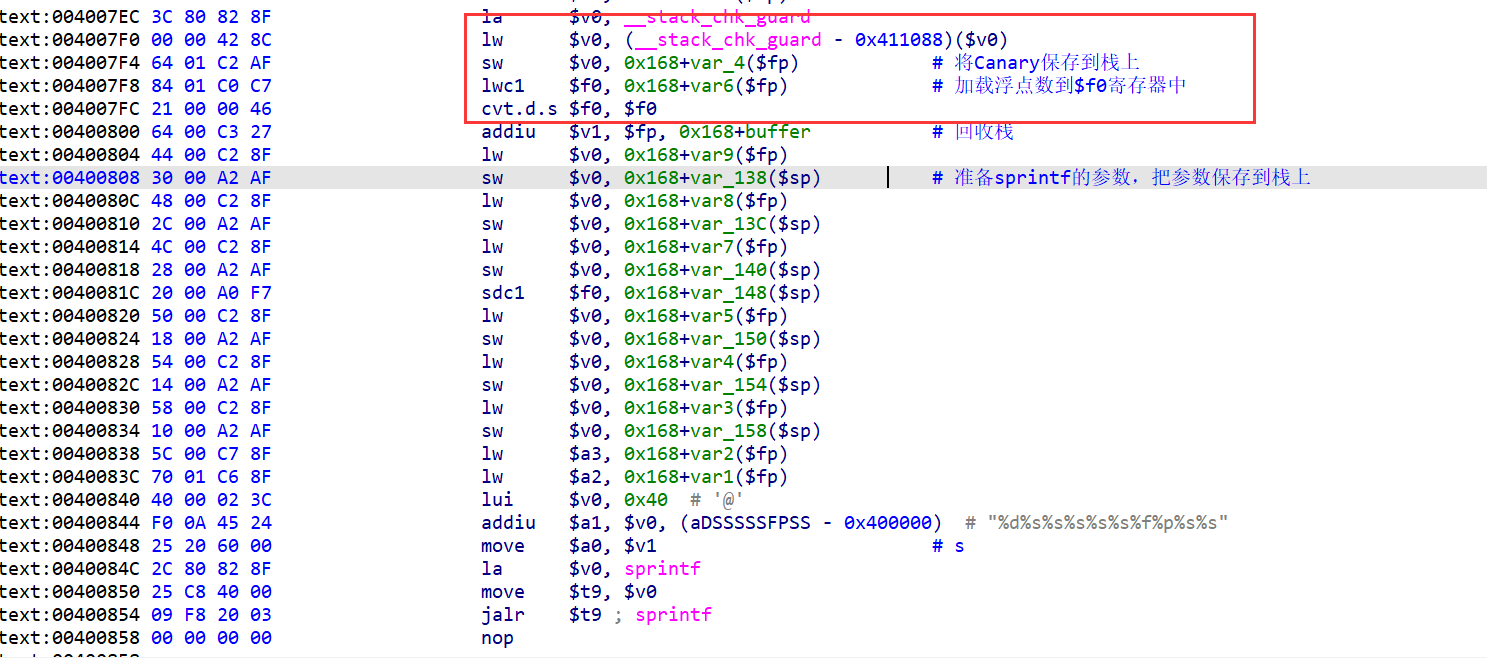
cvt.d.s $f0, $f1:该指令的全称为Convert Double to Single,将寄存器$f1的浮点数转换为整型保存在浮点寄存器$f0中。addiu $v1,$sp,0x168+buffer:前面见到的addiu只有两个操作数,而这里有3个操作数,当出现后者这种情况时,表示$v1 = $fp + 0x168 + buffer(buffer的地址)sdc1 $f0,0x18+var_148($sp),将浮点寄存器$f0的数据存到内存地址0x168+var_148($sp)中。
末尾还有一段检查Canary是否被篡改:
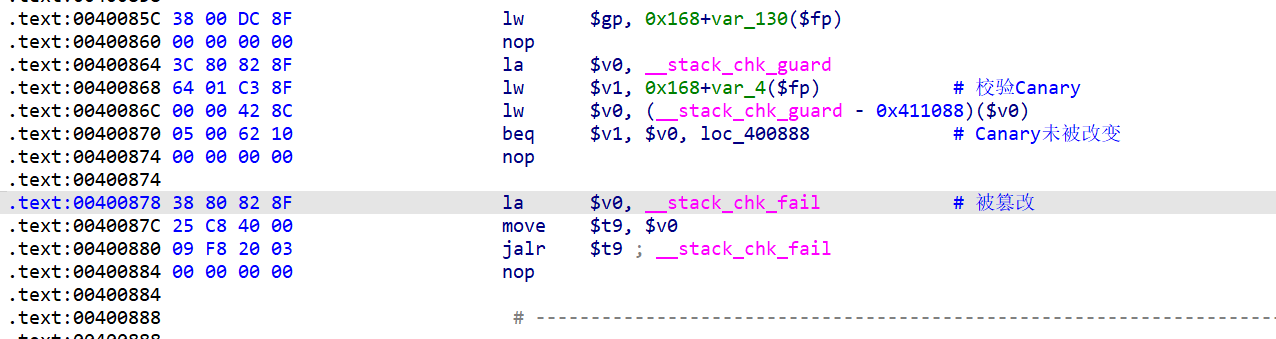
MIPS的函数调用
先介绍两个概念
叶子函数
- 某个函数中不会再调用其他的函数,称为“叶子函数”。
- 非叶子函数:某个函数会调用其它函数,可以称这个函数为“非叶子函数”。
源码:
1 |
|
编译为可执行文件:
1 | mipsel-linux-gnu-gcc -g leaf_function.c -o leaf_function_MIPSEL_32 |
qemu模拟运行:
1 | qemu-mipsel-static -L /usr/mipsel-linux-gnu -g 1234 ./leaf_function_MIPSEL_32 |
gdb脚本:
1 | file ./leaf_function_MIPSEL_32 |
gdb远程调试:
1 | gdb-multiarch -x leaf_function_MIPSEL_32_script.gdb |
gdb会断在main函数开头
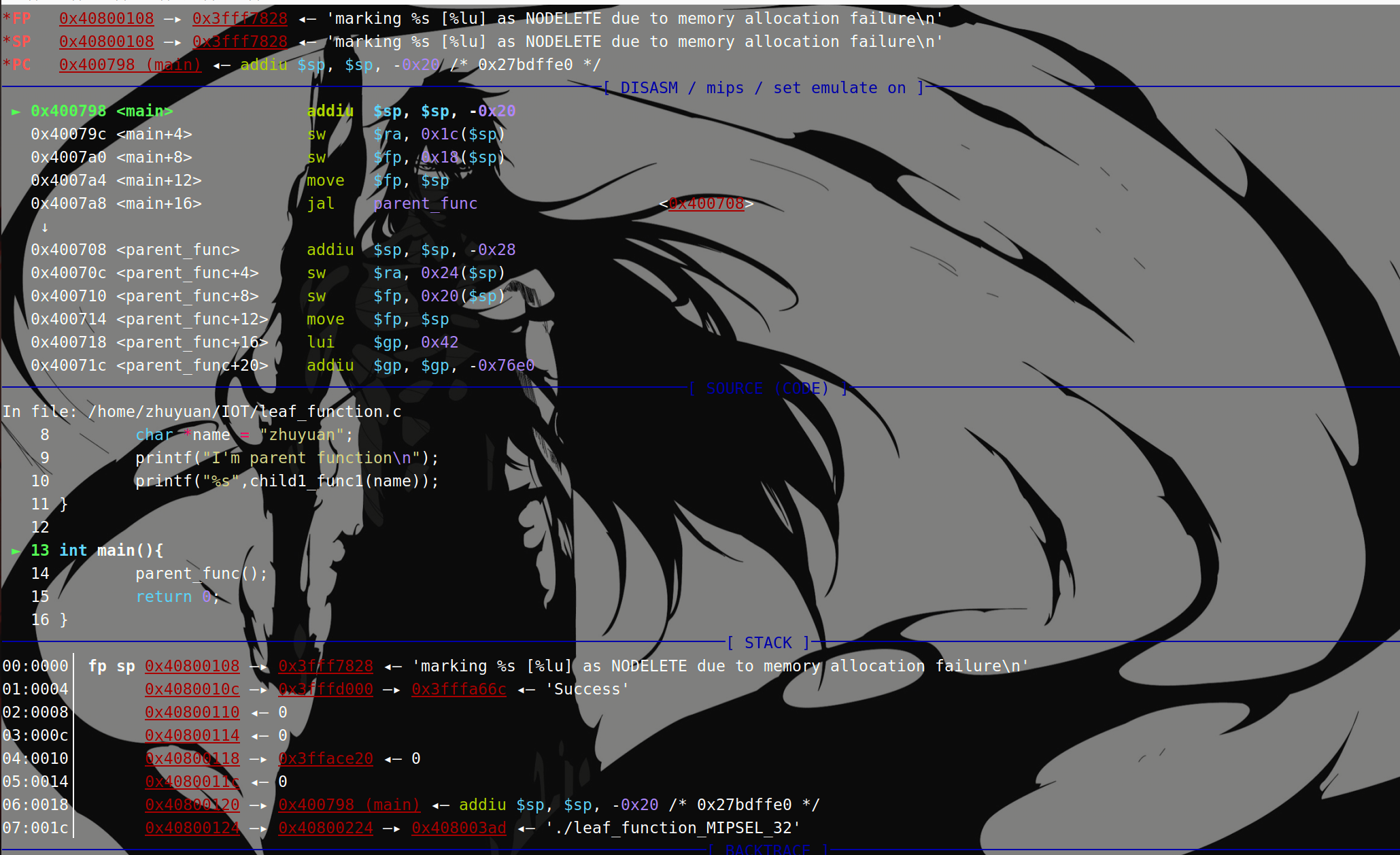
- 开启main函数栈帧:
addiu $sp, -0x20
- 保存main函数的返回地址
$ra(Return Address Register)到stack中0x1c($sp),sw$ra, 0x18+var_s4($sp):
sw$fp, 0x18+var_s0($sp)与move$fp, $sp这两条语句十分的关键,因为$fp和$s8这两个寄存器在IDA和gdb中的表述方式不同
在IDA中并不会将$8显示出来,所以对$fp的操作影响的都是$fp而非$s8。
在gdb中会将$s8和$fp寄存器一起显示出来。并且在gdb中,所有对于$fp寄存器的操作都是对$s8的操作。也就是说,当使用$fp寻址时用的是$s8而不是$fp。赋值操作等等也是同样的。
解释一下出现这种情况的原因:
第30号通用寄存器可以被叫做$fp寄存器或者是$s8寄存器,所以它们用的是同一个“实体物理结构”,造成这种混乱原因得归结于不同编译器对该”物理结构”的使用,GNU MIPS C编译器将它用作帧指针(即$fp),而SGI的C编译器则将其当做保存寄存器使用【$s8】,后者的使用方法虽然节省了调用和返回开销,但是增加了代码生成的复杂性。我们所使用的是GNU编译器:
根据上述描述,得出几个结论:
- 寄存器
$s8和$fp本身是同一个寄存器,只不过是两个名字,既可以用于Saved也可以用于Frame Pointer。 - 对于使用GNU编译的可执行文件来说,在IDA中只会显示
$fp寄存器,猜测这才是比较正统的显示方式 - gdb的显示寄存器的方式估计是为了对SGI编译出来的程序有更好的兼容性,并且在调试GNU的程序时需要gdb自己协调
$fp和$s8的显示方式与显示关系,因为每个指令语句的含义都是相同的。
需要注意的是,在执行main函数时,无论哪一种表述方式,存放到栈上的都是0。即,MIPS的函数在addiu开栈帧之后会立刻move移动$fp到$sp的位置。

总结:帧指针($fp)在调用过程中起着锚定的作用,在子过程被调用时会将旧的的$fp压栈,再将$fp指向新产生栈帧固定位置,这样当前栈帧中就有了$fp当作哨兵,起到两个作用:
- 无论
$sp怎么变,但只要知道栈中保存的数据相对于$fp的偏移,就可以将内存中的数据顺利取出。 - 如果
$sp在子过程为自己分配了栈空间后又发生了变化,那么在子过程返回前,$fp还需要帮$sp恢复原值($sp恢复原值也就是释放了当前子过程占用的栈空间)。
调用非叶子函数parent_func,先看IDA:执行jal指令后会将返回地址存入到$ra中:
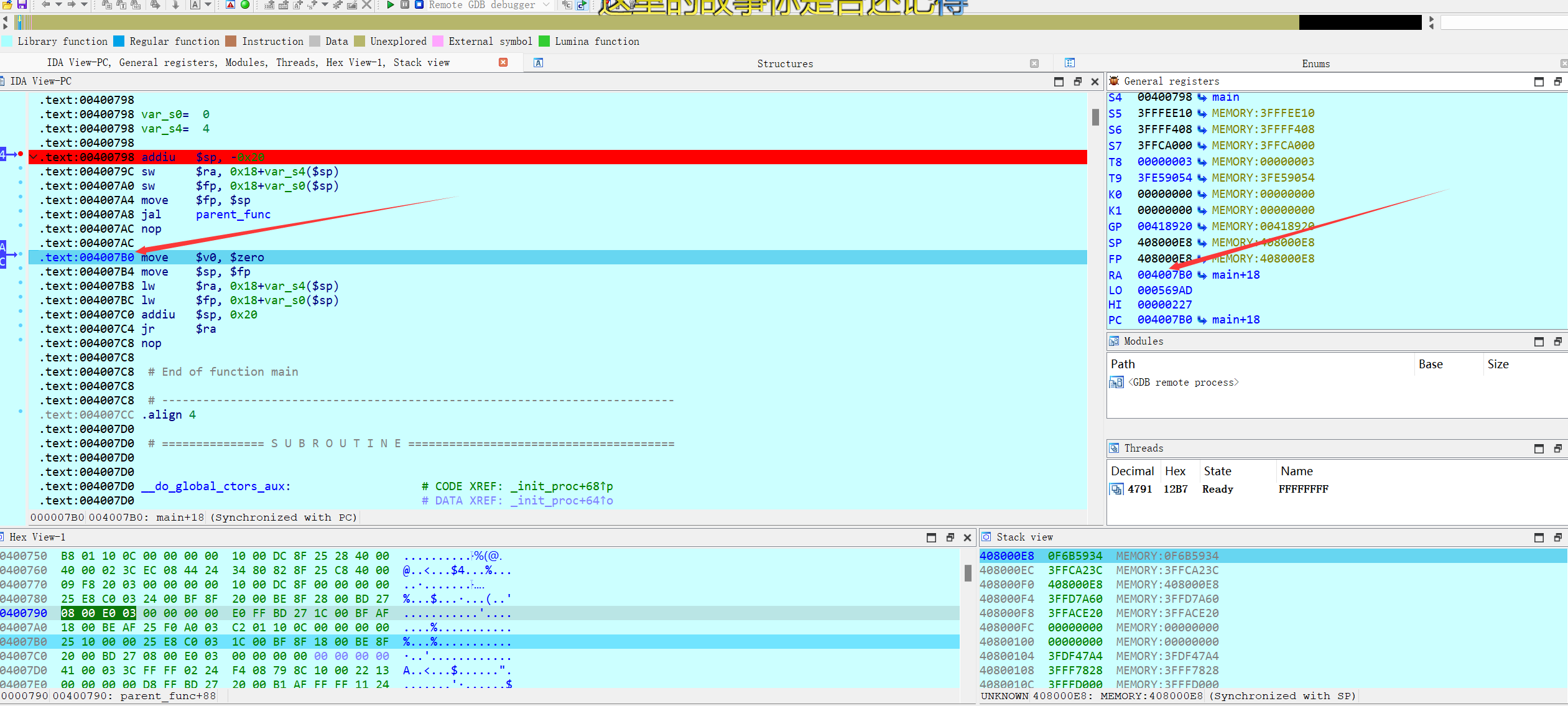
然后Nop滑动到parent_func函数执行代码:
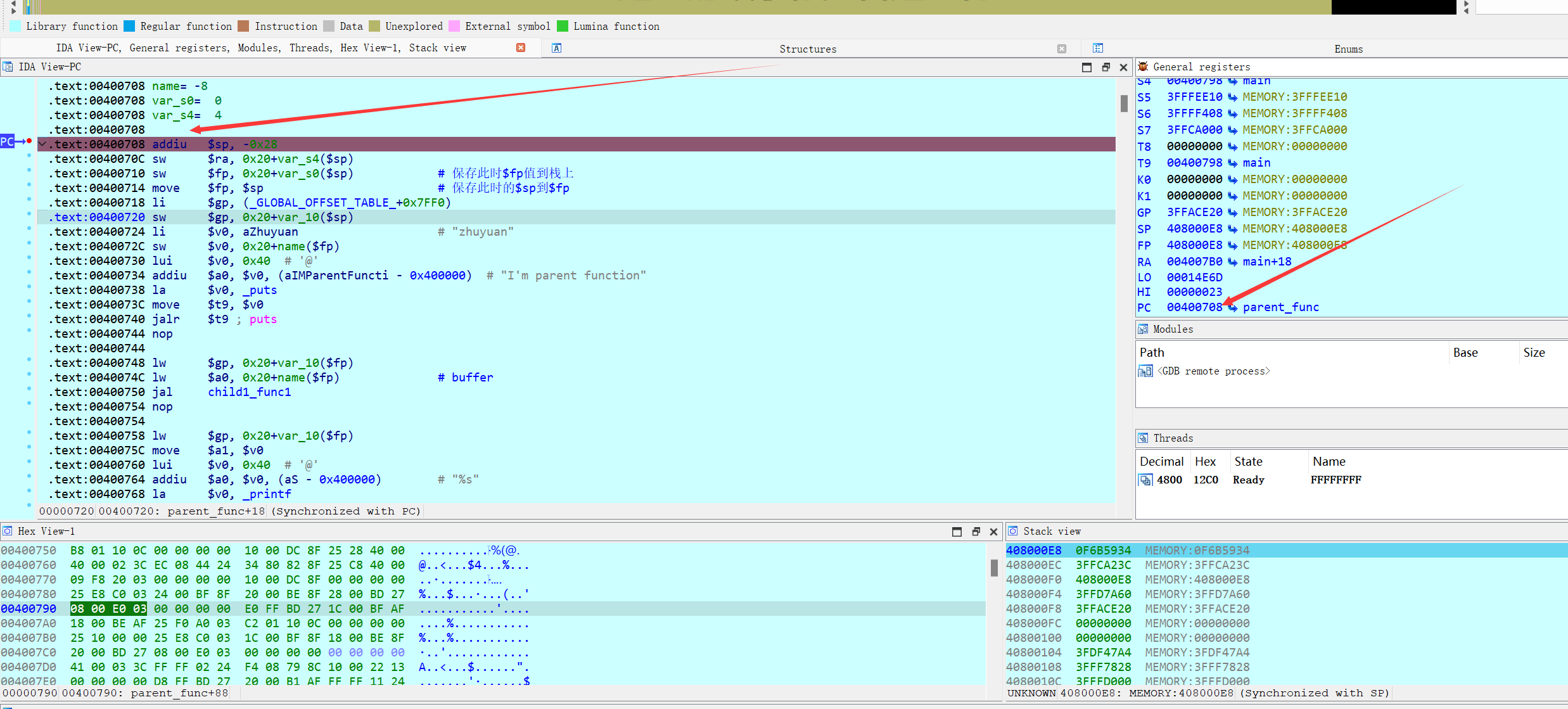
总之,在IDA中,当函数A调用其它函数B时,函数调用指令如jal会将函数B的返回地址存入$ra中,然后nop滑动执行函数B;调用前后$sp和$fp值不变且相等。
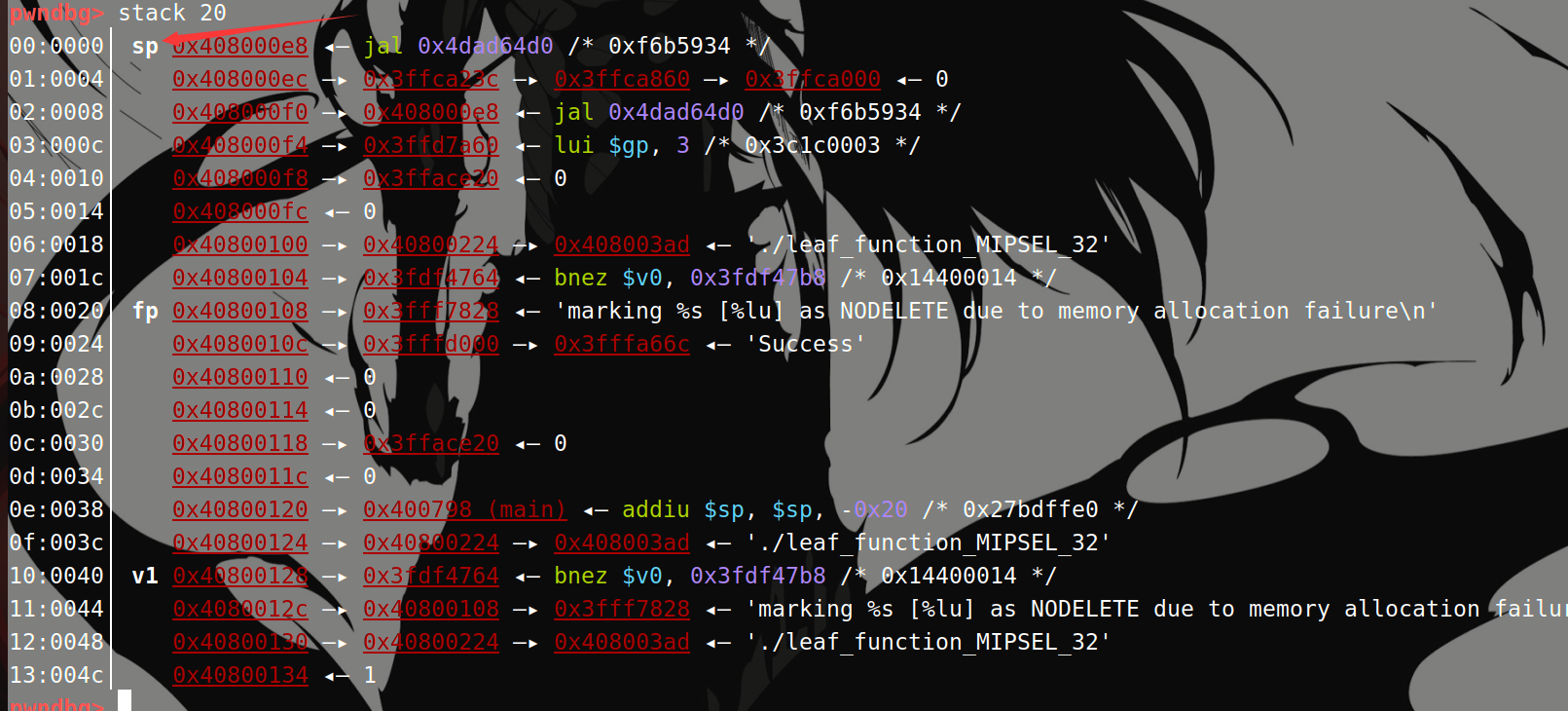
然后看gdb中,在parent_func的起始地址0x0400708下断点,调用后处除了和IDA一样的$ra发生变化,gdb显示的$fp也发生了变化,此时的$fp,$s8,$sp值相等:
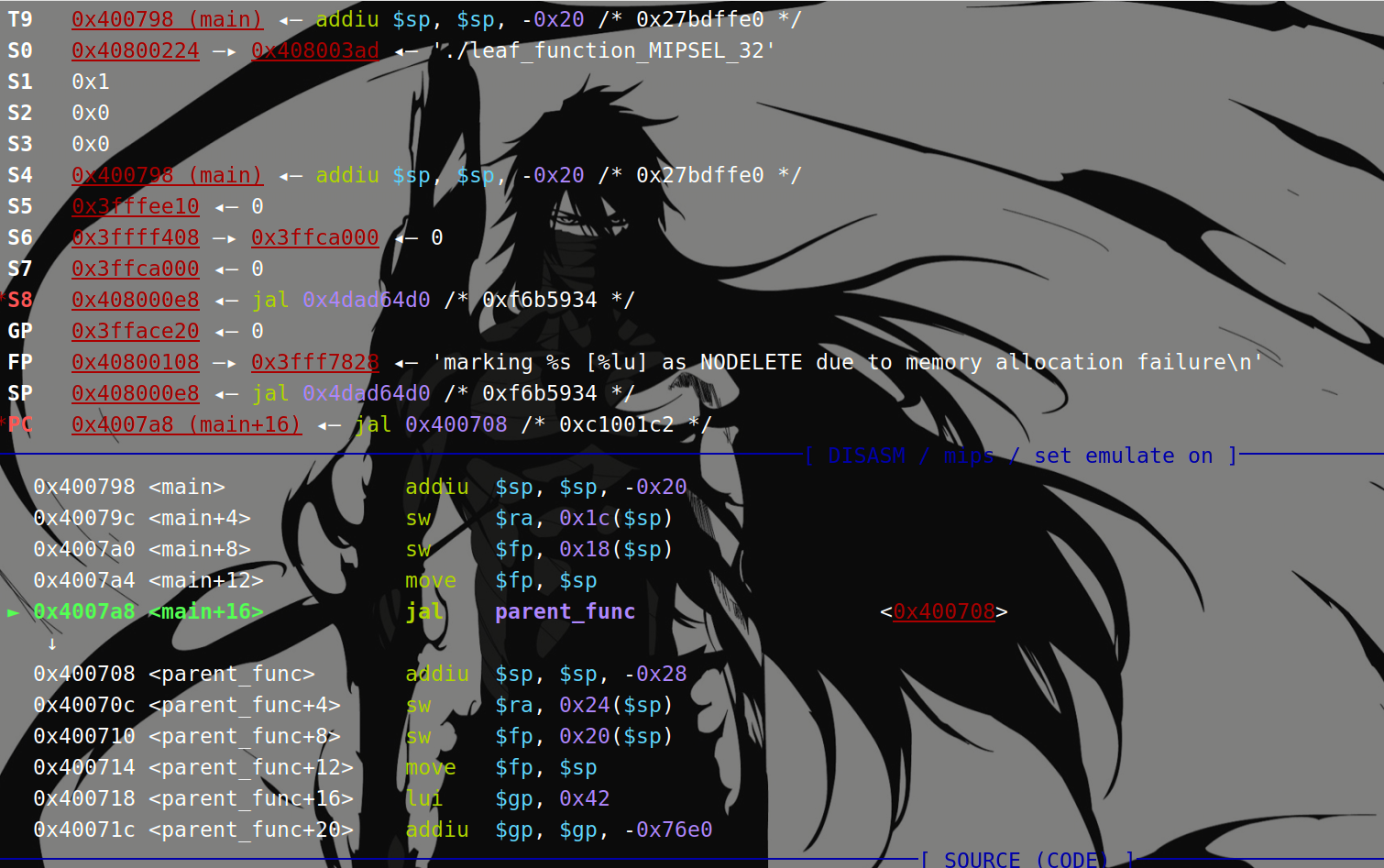
执行jal之后:
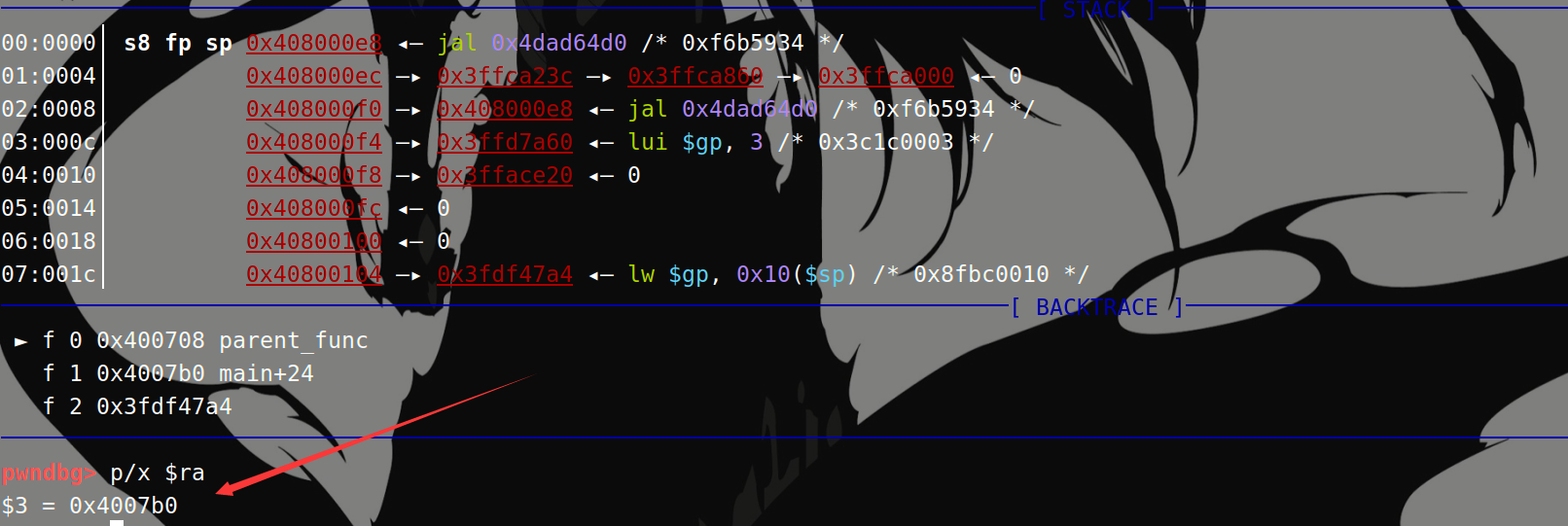
紧接着执行:

- 开辟栈帧
- 保存返回地址到栈上
- 保存栈底到栈上
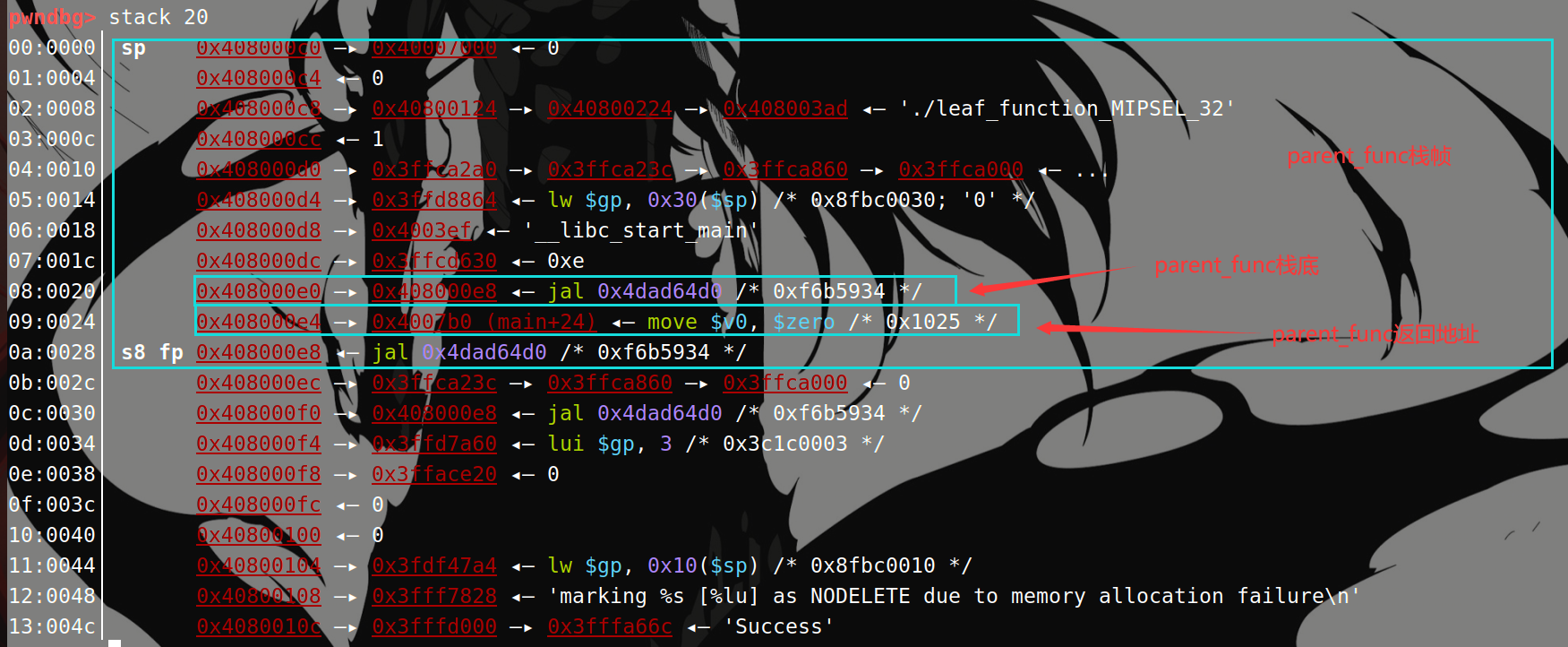 与调用main函数时不同,只有在调用main函数时保存的栈底才是0。
与调用main函数时不同,只有在调用main函数时保存的栈底才是0。
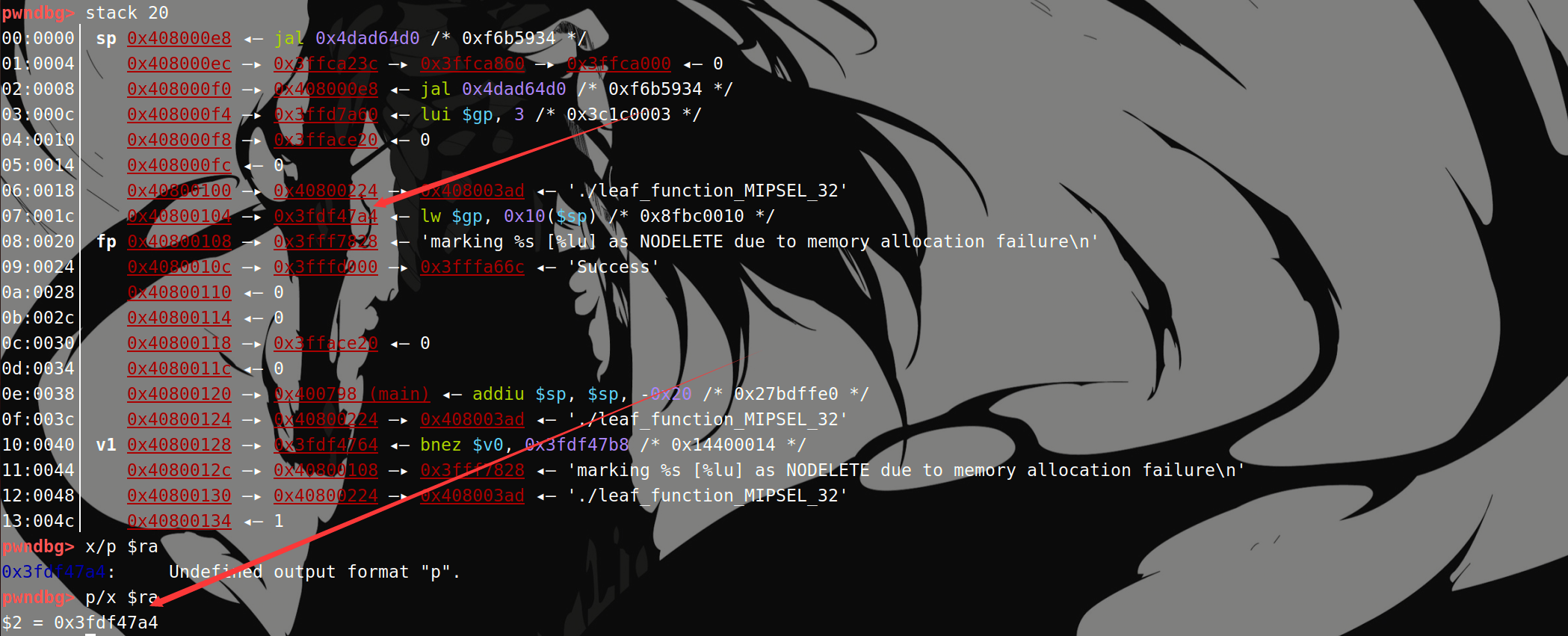
执行move之后:

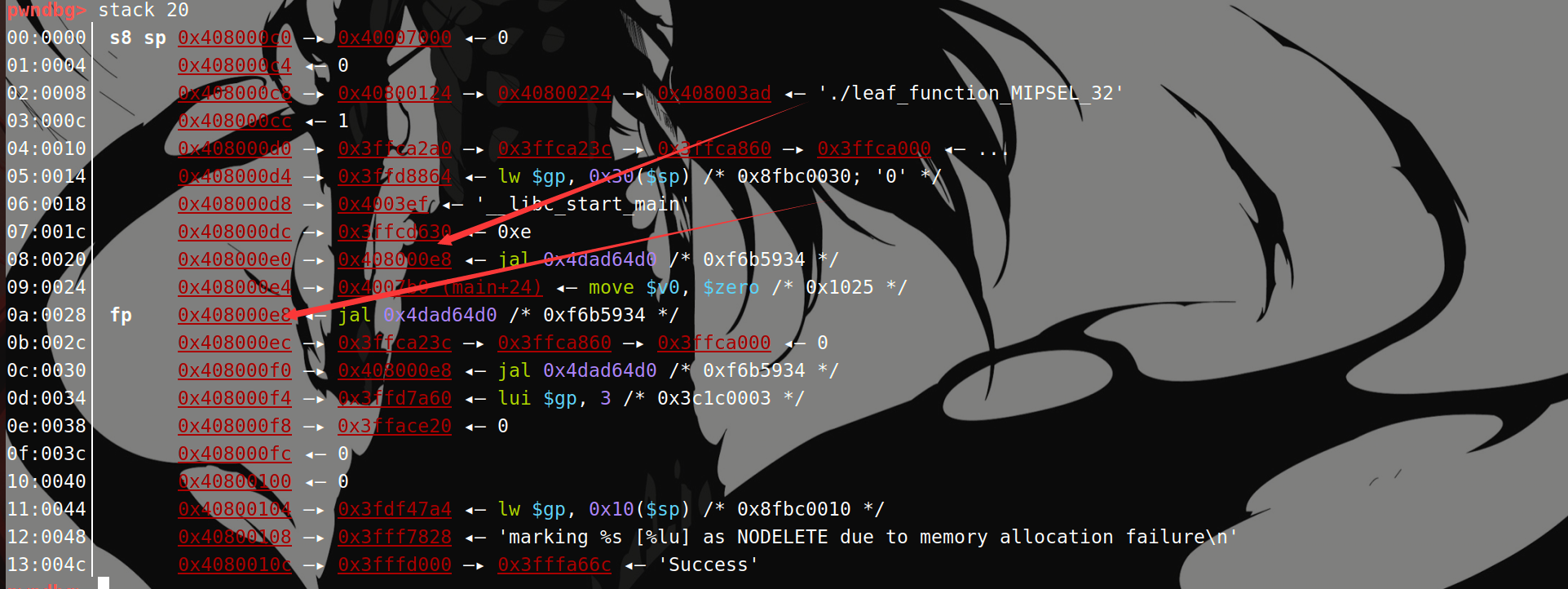
$sp到$fp之前的内存为当前函数的栈帧。
所以这种显示方式:
$8称为事实上的栈底。$fp表示指向旧的$fp。$sp还是意义上的栈顶。
移动栈底之后开始调用puts函数(编译器优化,把printf优化为puts函数):
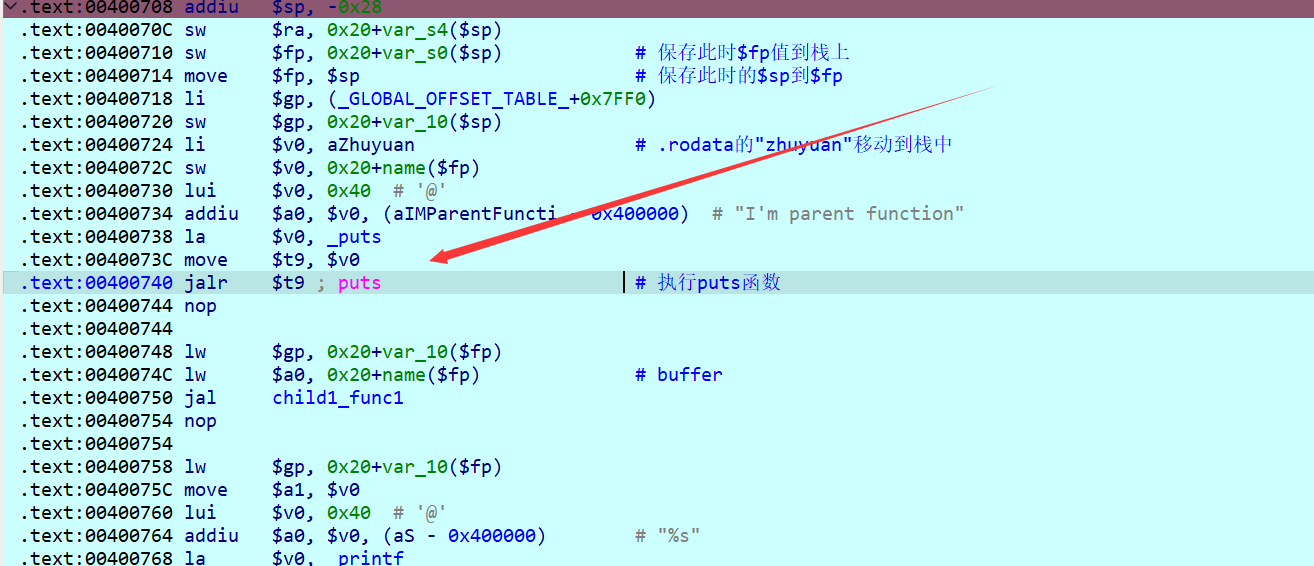
准备调用child_func1函数:

调用child_func1叶子函数:

可以看到叶子函数只保存了$fp,并没有保存返回地址$ra到stack上
函数将要结束时,恢复原$sp,并且回收栈帧,保持栈平衡:
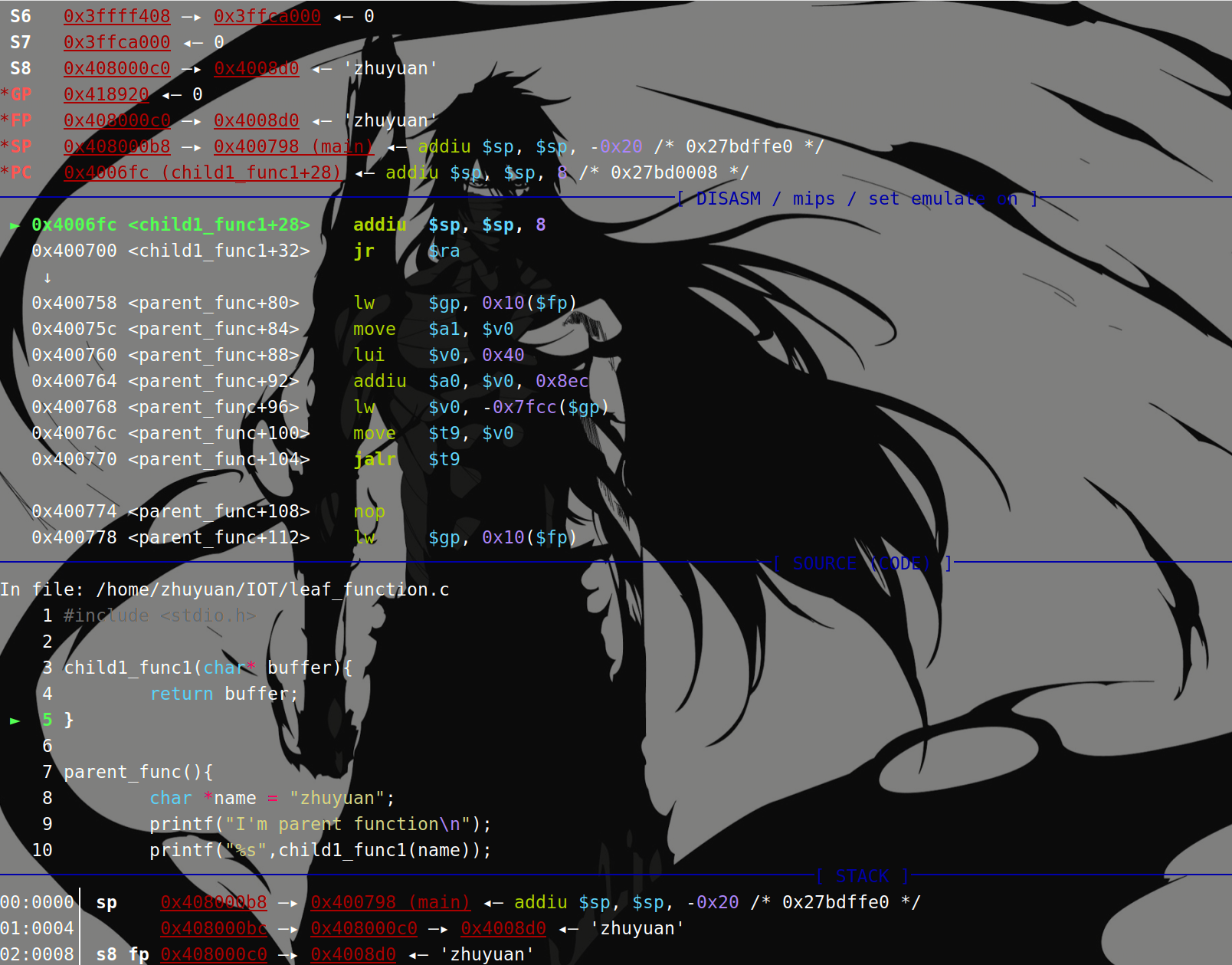
addiu $sp,$p,8 之后:
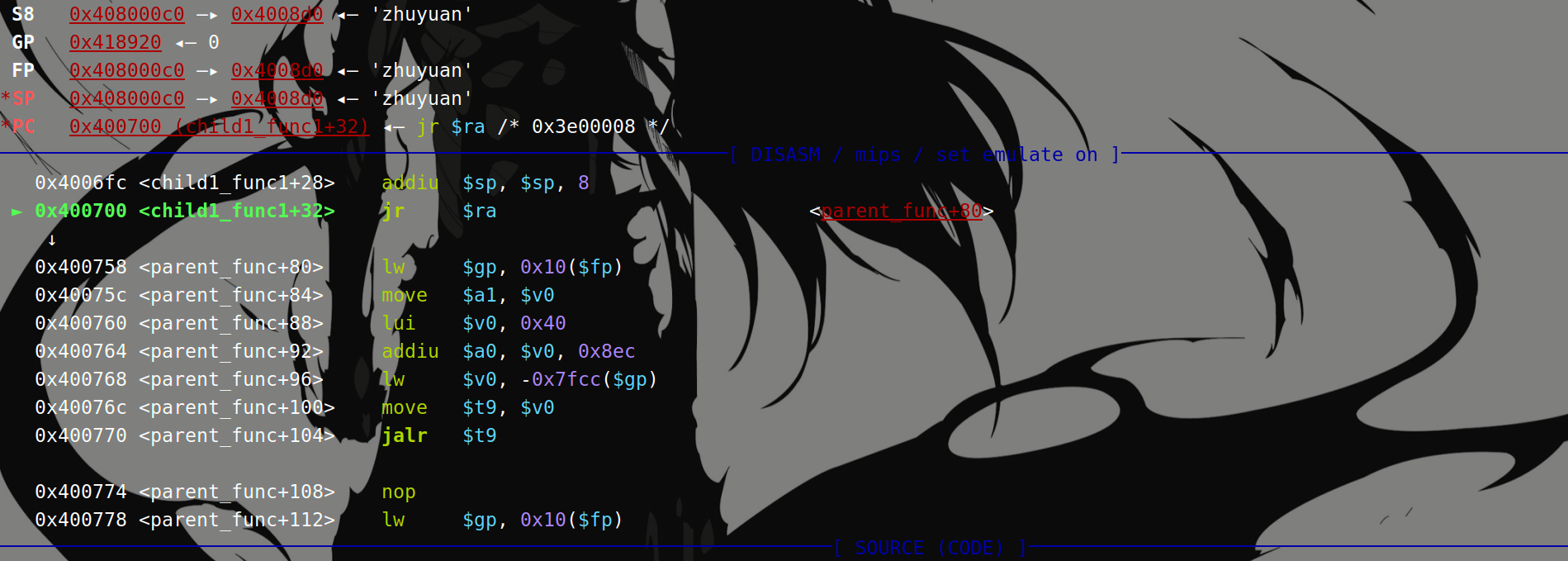
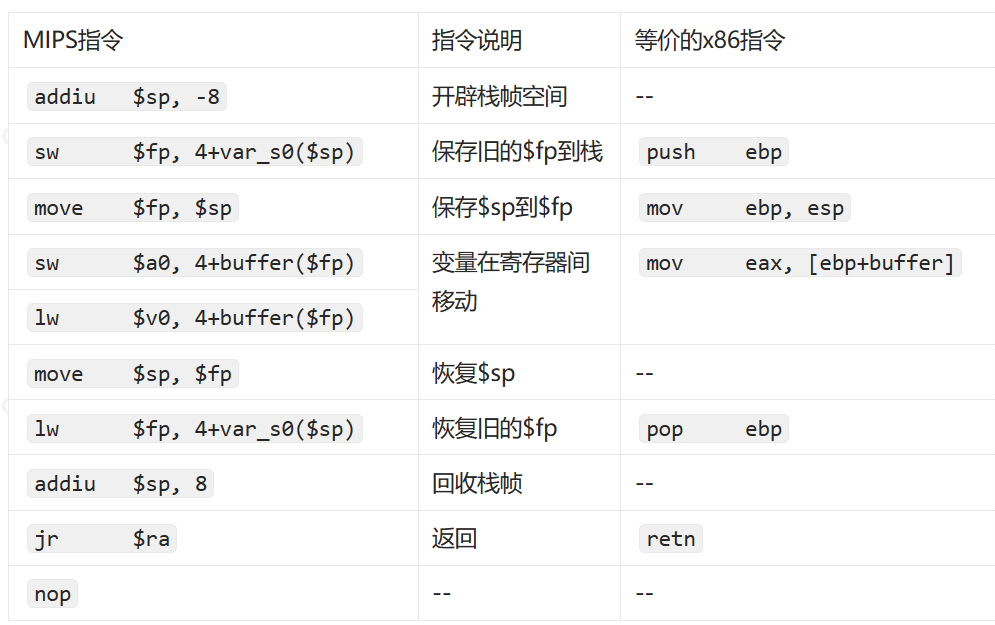
叶子函数和非叶子函数的返回方式不相同,现在A函数调用了B函数,如果B函数是叶子函数,直接使用 jr $ra指令返回函数A;如果函数B是非叶子函数,则函数B先从堆栈中取出被保存在堆栈上的返回地址,然后将返回地址存入寄存器$ra,再使用 jr $ra指令返回函数A:
叶子函数返回:

非叶子函数返回:










